Chapter 4 Point Data
4.1 Introduction
We now have all of our data prepared for harp and we are ready to work with. That work includes undertsanding how harp data are structured, how to plot forecast data, how to manipulate the data, and verification.
We’ll be making use of all of the harp packages in this section, so we can just attach the full set of harp packages (and as always tidyverse and here)
4.2 Deterministic data
Let’s start with our deterministic data from the AROME Arctic model and member 0 of MEPS. First we load the data into our environment with the function read_point_forecast. As with other functions, we need to tell the function the start and end dates that we want, the names of the models, the parameter, the frequency of the forecasts, the path to the data and whether it is deterministic or ensemble data.
s10m <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = c("AROME_Arctic_prod", "MEPS_prod"),
fcst_type = "det",
parameter = "S10m",
by = "6h",
file_path = here("data/FCTABLE/deterministic")
)
s10m## ● AROME_Arctic_prod
## # A tibble: 17,612 x 9
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1002 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1003 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1004 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1006 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1007 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1008 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1009 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1011 S10m
## # … with 17,602 more rows, and 4 more variables: AROME_Arctic_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>
##
## ● MEPS_prod
## # A tibble: 81,804 x 9
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1021 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1022 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## # … with 81,794 more rows, and 4 more variables: MEPS_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>You will see that data are in two data frames in a list. This list is actually an object of class harp_fcst. Many of the functions in harp only work on harp_fcst objects. Many of the dplyr methods also work on harp_fcst objects. The forecast data are in the last column with the suffix "_det".
Let’s take a look at some of the things you can do with harp_fcst objects. First expand_data
## ● AROME_Arctic_prod
## # A tibble: 17,612 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1002 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1003 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1004 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1006 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1007 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1008 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1009 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1011 S10m
## # … with 17,602 more rows, and 9 more variables: AROME_Arctic_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, fc_year <dbl>,
## # fc_month <dbl>, fc_day <int>, fc_hour <int>, fc_minute <int>
##
## ● MEPS_prod
## # A tibble: 81,804 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1021 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1022 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## # … with 81,794 more rows, and 9 more variables: MEPS_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, fc_year <dbl>,
## # fc_month <dbl>, fc_day <int>, fc_hour <int>, fc_minute <int>## ● AROME_Arctic_prod
## # A tibble: 17,612 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1002 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1003 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1004 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1006 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1007 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1008 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1009 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1011 S10m
## # … with 17,602 more rows, and 9 more variables: AROME_Arctic_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, valid_year <dbl>,
## # valid_month <dbl>, valid_day <int>, valid_hour <int>, valid_minute <int>
##
## ● MEPS_prod
## # A tibble: 81,804 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1021 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1022 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## # … with 81,794 more rows, and 9 more variables: MEPS_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, valid_year <dbl>,
## # valid_month <dbl>, valid_day <int>, valid_hour <int>, valid_minute <int>With the year, month, day, hour and minute now available, it’s easier to filter the data if you’d like. For example, if you just want the forecast wind speed at 15:00 UTC on 17 Feb 2019 for station ID 1010, which we is on Andøya, we could do something like
expand_date(s10m, validdate) %>%
filter(
SID == 1010,
valid_year == 2019,
valid_month == 2,
valid_day == 17,
valid_hour == 15
)## ● AROME_Arctic_prod
## # A tibble: 3 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 15:00:00 15 1010 S10m
## 2 2019-02-17 06:00:00 2019-02-17 15:00:00 9 1010 S10m
## 3 2019-02-17 12:00:00 2019-02-17 15:00:00 3 1010 S10m
## # … with 9 more variables: AROME_Arctic_prod_det <dbl>, fcst_cycle <chr>,
## # model_elevation <dbl>, units <chr>, valid_year <dbl>, valid_month <dbl>,
## # valid_day <int>, valid_hour <int>, valid_minute <int>
##
## ● MEPS_prod
## # A tibble: 3 x 14
## fcdate validdate leadtime SID parameter MEPS_prod_det
## <dttm> <dttm> <int> <int> <chr> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 15:00:00 15 1010 S10m 5.99
## 2 2019-02-17 06:00:00 2019-02-17 15:00:00 9 1010 S10m 4.58
## 3 2019-02-17 12:00:00 2019-02-17 15:00:00 3 1010 S10m 3.30
## # … with 8 more variables: fcst_cycle <chr>, model_elevation <dbl>,
## # units <chr>, valid_year <dbl>, valid_month <dbl>, valid_day <int>,
## # valid_hour <int>, valid_minute <int>Equally, we could just get the data for one forecast
expand_date(s10m, fcdate) %>%
filter(
SID == 1010,
fc_year == 2019,
fc_month == 2,
fc_day == 17,
fc_hour == 12
) %>%
mutate(validdate = unix2datetime(validdate))## ● AROME_Arctic_prod
## # A tibble: 17 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 12:00:00 2019-02-17 12:00:00 0 1010 S10m
## 2 2019-02-17 12:00:00 2019-02-17 15:00:00 3 1010 S10m
## 3 2019-02-17 12:00:00 2019-02-17 18:00:00 6 1010 S10m
## 4 2019-02-17 12:00:00 2019-02-17 21:00:00 9 1010 S10m
## 5 2019-02-17 12:00:00 2019-02-18 00:00:00 12 1010 S10m
## 6 2019-02-17 12:00:00 2019-02-18 03:00:00 15 1010 S10m
## 7 2019-02-17 12:00:00 2019-02-18 06:00:00 18 1010 S10m
## 8 2019-02-17 12:00:00 2019-02-18 09:00:00 21 1010 S10m
## 9 2019-02-17 12:00:00 2019-02-18 12:00:00 24 1010 S10m
## 10 2019-02-17 12:00:00 2019-02-18 15:00:00 27 1010 S10m
## 11 2019-02-17 12:00:00 2019-02-18 18:00:00 30 1010 S10m
## 12 2019-02-17 12:00:00 2019-02-18 21:00:00 33 1010 S10m
## 13 2019-02-17 12:00:00 2019-02-19 00:00:00 36 1010 S10m
## 14 2019-02-17 12:00:00 2019-02-19 03:00:00 39 1010 S10m
## 15 2019-02-17 12:00:00 2019-02-19 06:00:00 42 1010 S10m
## 16 2019-02-17 12:00:00 2019-02-19 09:00:00 45 1010 S10m
## 17 2019-02-17 12:00:00 2019-02-19 12:00:00 48 1010 S10m
## # … with 9 more variables: AROME_Arctic_prod_det <dbl>, fcst_cycle <chr>,
## # model_elevation <dbl>, units <chr>, fc_year <dbl>, fc_month <dbl>,
## # fc_day <int>, fc_hour <int>, fc_minute <int>
##
## ● MEPS_prod
## # A tibble: 17 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 12:00:00 2019-02-17 12:00:00 0 1010 S10m
## 2 2019-02-17 12:00:00 2019-02-17 15:00:00 3 1010 S10m
## 3 2019-02-17 12:00:00 2019-02-17 18:00:00 6 1010 S10m
## 4 2019-02-17 12:00:00 2019-02-17 21:00:00 9 1010 S10m
## 5 2019-02-17 12:00:00 2019-02-18 00:00:00 12 1010 S10m
## 6 2019-02-17 12:00:00 2019-02-18 03:00:00 15 1010 S10m
## 7 2019-02-17 12:00:00 2019-02-18 06:00:00 18 1010 S10m
## 8 2019-02-17 12:00:00 2019-02-18 09:00:00 21 1010 S10m
## 9 2019-02-17 12:00:00 2019-02-18 12:00:00 24 1010 S10m
## 10 2019-02-17 12:00:00 2019-02-18 15:00:00 27 1010 S10m
## 11 2019-02-17 12:00:00 2019-02-18 18:00:00 30 1010 S10m
## 12 2019-02-17 12:00:00 2019-02-18 21:00:00 33 1010 S10m
## 13 2019-02-17 12:00:00 2019-02-19 00:00:00 36 1010 S10m
## 14 2019-02-17 12:00:00 2019-02-19 03:00:00 39 1010 S10m
## 15 2019-02-17 12:00:00 2019-02-19 06:00:00 42 1010 S10m
## 16 2019-02-17 12:00:00 2019-02-19 09:00:00 45 1010 S10m
## 17 2019-02-17 12:00:00 2019-02-19 12:00:00 48 1010 S10m
## # … with 9 more variables: MEPS_prod_det <dbl>, fcst_cycle <chr>,
## # model_elevation <dbl>, units <chr>, fc_year <dbl>, fc_month <dbl>,
## # fc_day <int>, fc_hour <int>, fc_minute <int>harp doesn’t yet include any functions for plotting deterministic forecasts, but we can easily make the data into a single data frame using bind_fcst.
bind_rows(
AROME_Arctic_prod = rename(s10m$AROME_Arctic_prod, forecast = AROME_Arctic_prod_det),
MEPS_prod = rename(s10m$MEPS_prod, forecast = MEPS_prod_det),
.id = "mname"
)## # A tibble: 99,416 x 10
## mname fcdate validdate leadtime SID parameter
## <chr> <dttm> <dttm> <int> <int> <chr>
## 1 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1002 S10m
## 3 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1003 S10m
## 4 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1004 S10m
## 5 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1006 S10m
## 6 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1007 S10m
## 7 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1008 S10m
## 8 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1009 S10m
## 9 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 10 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1011 S10m
## # … with 99,406 more rows, and 4 more variables: forecast <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>You will also find in R directory a function, bind_fcst that does this binding for you - this function will be part of harp soon.
## # A tibble: 99,416 x 10
## mname fcdate validdate leadtime SID parameter
## <chr> <dttm> <dttm> <int> <int> <chr>
## 1 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1002 S10m
## 3 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1003 S10m
## 4 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1004 S10m
## 5 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1006 S10m
## 6 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1007 S10m
## 7 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1008 S10m
## 8 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1009 S10m
## 9 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 10 AROM… 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1011 S10m
## # … with 99,406 more rows, and 4 more variables: forecast <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>Your turn:
- Plot the the forecast wind speed at REIPA for both AROME_Arctic_prod and MEPS_prod for each fcst_cycle as a function of validdate. [You can get the SID for REIPA from the built in list of stations which is in the variable station_list]
Solution:
reipa_sid <- filter(station_list, name == "REIPA") %>%
pull(SID)
bind_fcst(s10m) %>%
filter(SID == reipa_sid) %>%
mutate(validdate = unix2datetime(validdate)) %>%
ggplot(aes(validdate, forecast, colour = fcst_cycle)) +
geom_line() +
facet_wrap(vars(mname), ncol = 1) +
scale_x_datetime(
breaks = lubridate::ymd_hm(seq_dates(2019021706, 2019021918, "12h"))
) +
labs(
x = "Date-time",
y = bquote("Wind speed [ms"^-1*"]"),
colour = "Forecast cycle",
title = "Forecast Wind Speed at REIPA"
) +
theme_bw() +
theme(legend.position = "bottom")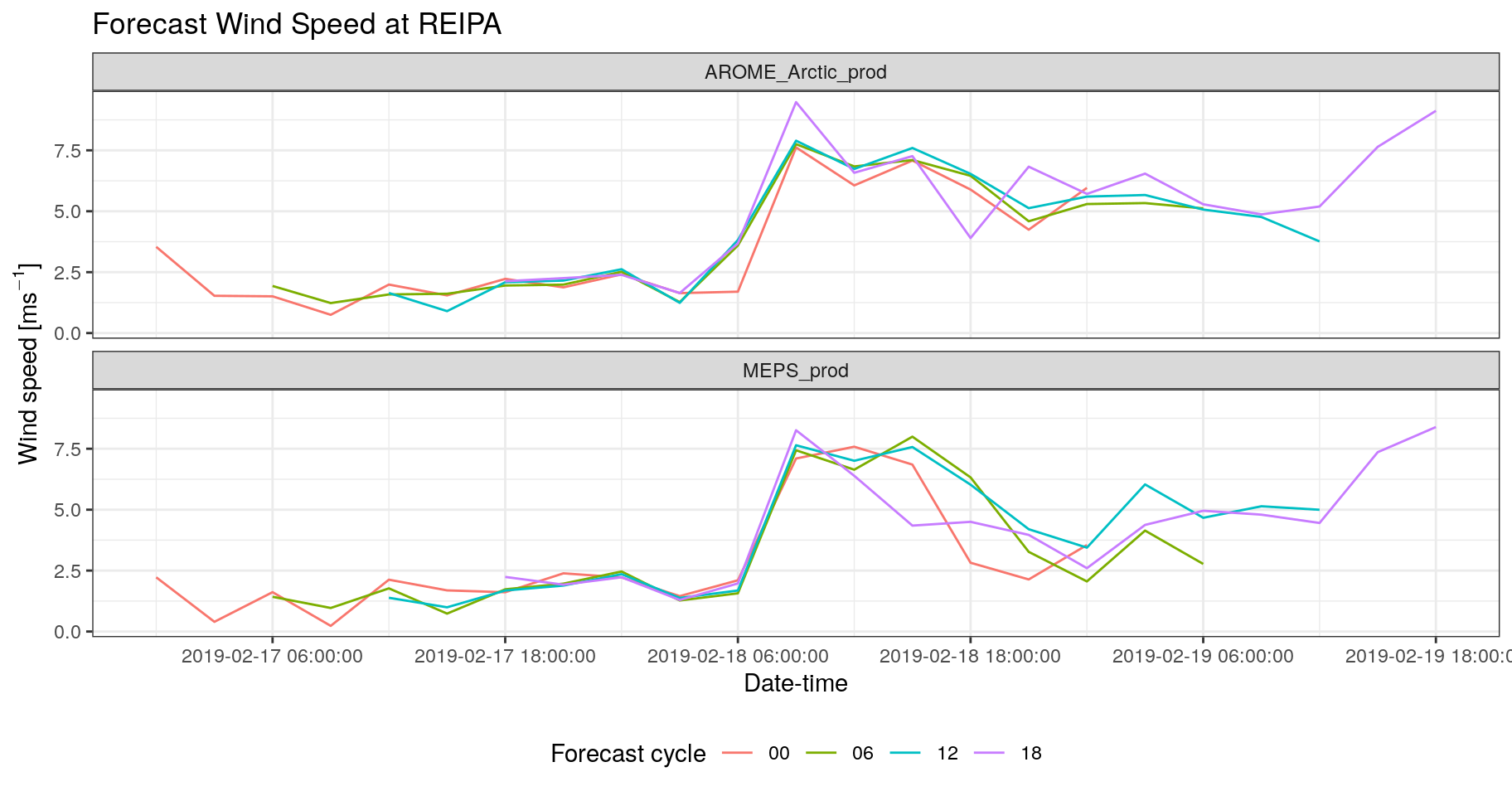
bind_fcst(s10m) %>%
filter(SID == reipa_sid) %>%
mutate(validdate = unix2datetime(validdate)) %>%
ggplot(aes(validdate, forecast, colour = mname)) +
geom_line() +
facet_wrap(vars(fcst_cycle), ncol = 1) +
scale_x_datetime(
breaks = lubridate::ymd_hm(seq_dates(2019021706, 2019021918, "12h"))
) +
labs(
x = "Date-time",
y = bquote("Wind speed [ms"^-1*"]"),
colour = "",
title = "Forecast Wind Speed at REIPA"
) +
theme_bw() +
theme(legend.position = "bottom")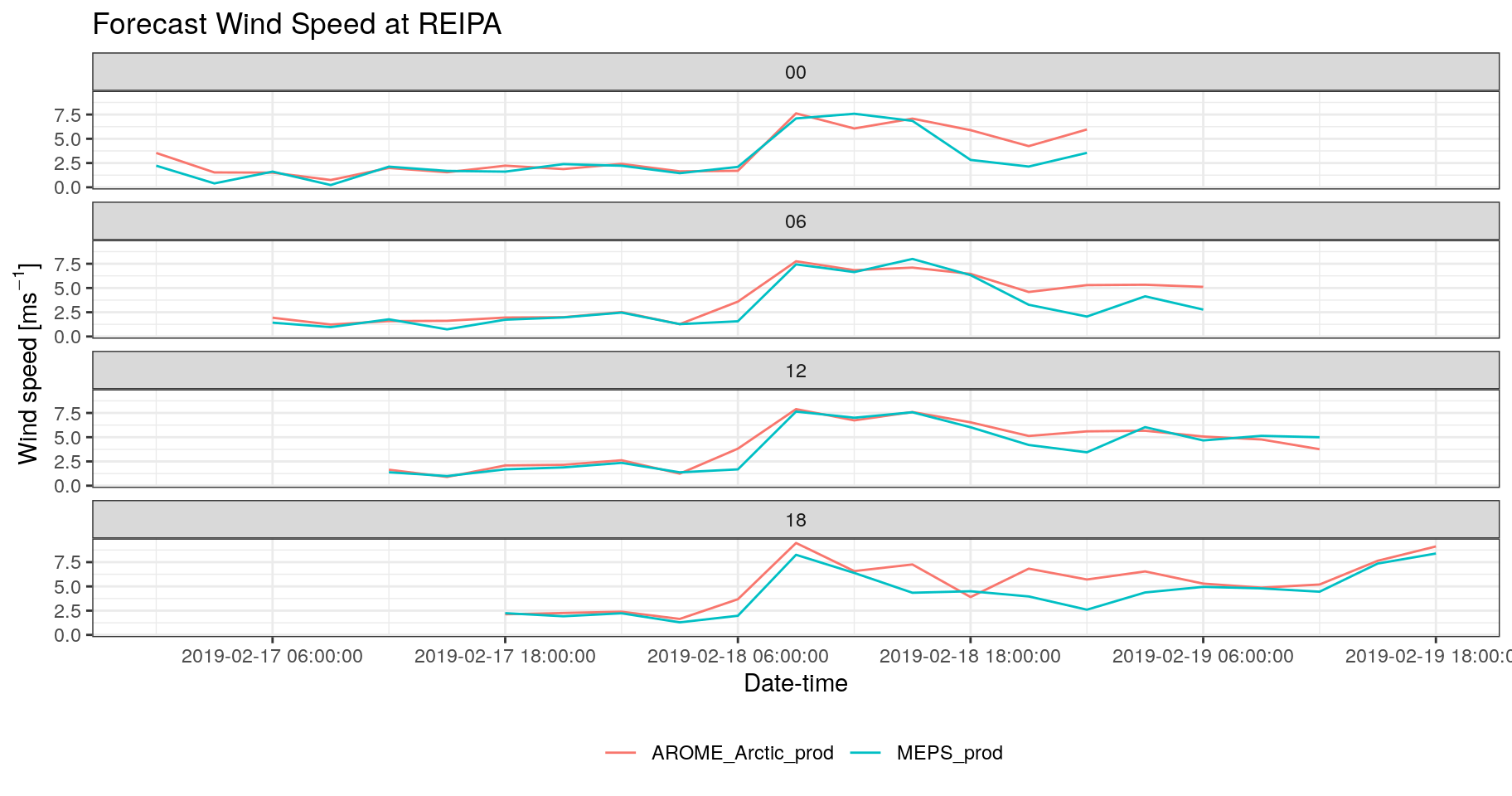
Now let’s read in some observations. To make sure we get the correct dates for the observations we can get the first and last validdates from the forecast. We could also extract the station IDs from the forecasts - which we can do with a little bit of “functional programming”.
station_ids <- map(s10m, pull, SID) %>%
reduce(union)
obs <- read_point_obs(
start_date = first_validdate(s10m),
end_date = last_validdate(s10m),
stations = station_ids,
parameter = "S10m",
obs_path = here("data/OBSTABLE")
)Now that we have the observations we can join them to our forecast data using the function join_to_fcst. This will take each of the data frames in our forecast list and perform an inner join with the observations - that means that only rows that are common to both data frames are kept.
We have now added an observations column to each of the forecasts, so we could also include the observations in our plots.
Your turn:
- Add observations as a geom_point to your plots. [hint: you can map an aesthetic to an individual geom]
Solution:
bind_fcst(s10m) %>%
filter(SID == reipa_sid) %>%
mutate(validdate = unix2datetime(validdate)) %>%
ggplot(aes(validdate, forecast, colour = mname)) +
geom_line() +
geom_point(aes(y = S10m, shape = "Observation"), colour = "blue") +
scale_shape_manual(values = 21) +
facet_wrap(vars(fcst_cycle), ncol = 1) +
scale_x_datetime(
breaks = lubridate::ymd_hm(seq_dates(2019021706, 2019021918, "12h"))
) +
labs(
x = "Date-time",
y = bquote("Wind speed [ms"^-1*"]"),
colour = "",
title = "Forecast Wind Speed at REIPA",
shape = ""
) +
theme_bw() +
theme(legend.position = "bottom")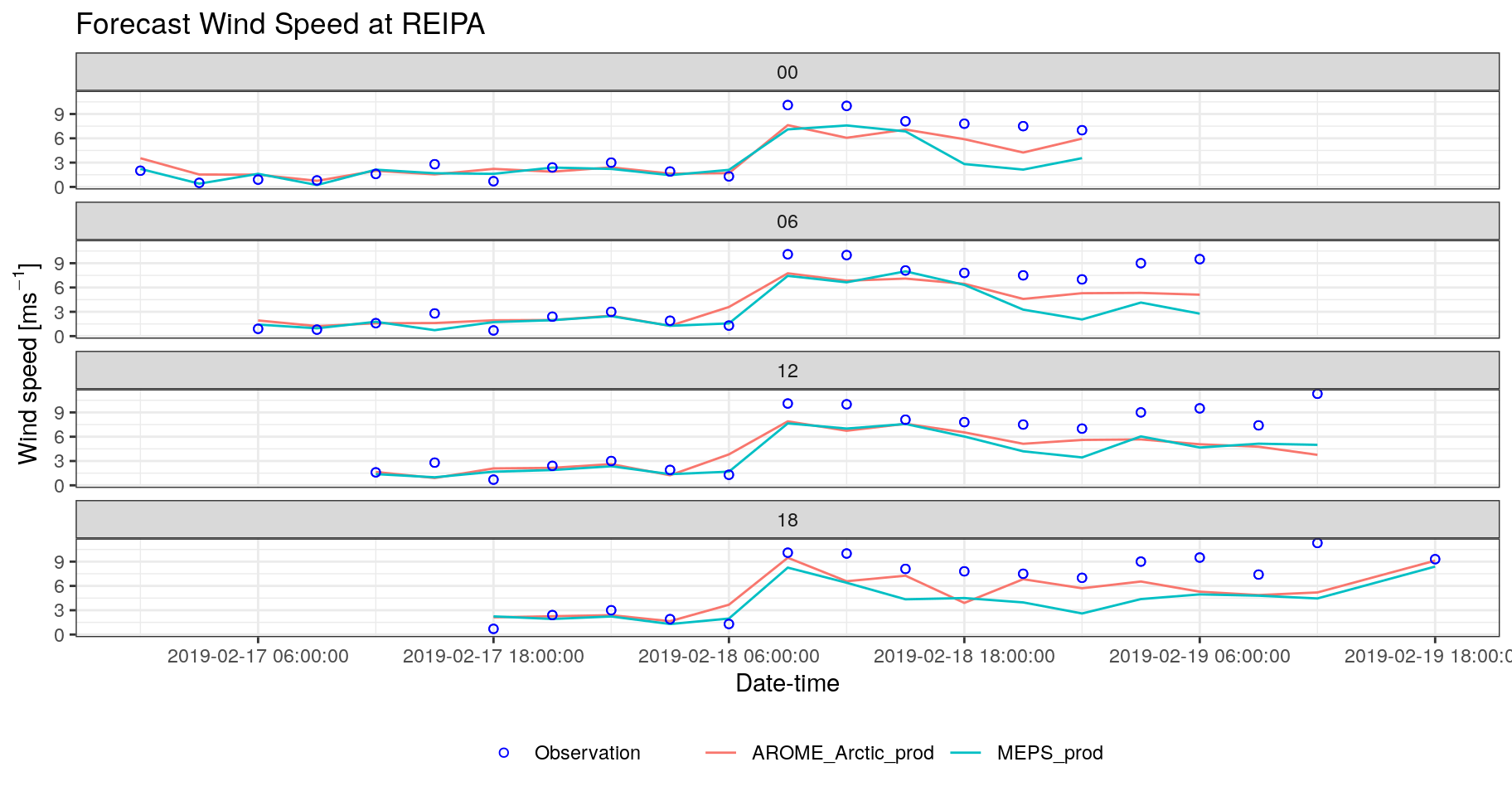
4.2.1 Verifying deterministic forecasts
Now that we have both forecasts and observations we can verify the forecasts. This is very simple in harp - we just run the function det_verify giving that data and telling it which column has the observations:
## $det_summary_scores
## # A tibble: 34 x 7
## mname leadtime num_cases bias rmse mae stde
## <chr> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 AROME_Arctic_prod 0 629 0.137 2.57 1.80 2.57
## 2 AROME_Arctic_prod 3 679 0.0580 2.34 1.60 2.34
## 3 AROME_Arctic_prod 6 622 0.0390 2.38 1.65 2.38
## 4 AROME_Arctic_prod 9 679 0.0942 2.08 1.42 2.08
## 5 AROME_Arctic_prod 12 628 0.169 2.24 1.53 2.24
## 6 AROME_Arctic_prod 15 675 0.295 2.17 1.53 2.15
## 7 AROME_Arctic_prod 18 630 0.319 2.22 1.53 2.20
## 8 AROME_Arctic_prod 21 676 0.480 2.23 1.61 2.17
## 9 AROME_Arctic_prod 24 628 0.388 2.34 1.61 2.31
## 10 AROME_Arctic_prod 27 674 0.538 2.39 1.69 2.33
## # … with 24 more rows
##
## $det_threshold_scores
## # A tibble: 0 x 0
##
## attr(,"parameter")
## [1] "S10m"
## attr(,"start_date")
## [1] "2019021700"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 828You will see that the output is a list of two data frames - one fore summary scores and one for threshold scores. The threshold scores data frame contains only missing data as we didn’t give the function any thresholds to verify for. However, that is easily done:
## $det_summary_scores
## # A tibble: 34 x 7
## mname leadtime num_cases bias rmse mae stde
## <chr> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 AROME_Arctic_prod 0 629 0.137 2.57 1.80 2.57
## 2 AROME_Arctic_prod 3 679 0.0580 2.34 1.60 2.34
## 3 AROME_Arctic_prod 6 622 0.0390 2.38 1.65 2.38
## 4 AROME_Arctic_prod 9 679 0.0942 2.08 1.42 2.08
## 5 AROME_Arctic_prod 12 628 0.169 2.24 1.53 2.24
## 6 AROME_Arctic_prod 15 675 0.295 2.17 1.53 2.15
## 7 AROME_Arctic_prod 18 630 0.319 2.22 1.53 2.20
## 8 AROME_Arctic_prod 21 676 0.480 2.23 1.61 2.17
## 9 AROME_Arctic_prod 24 628 0.388 2.34 1.61 2.31
## 10 AROME_Arctic_prod 27 674 0.538 2.39 1.69 2.33
## # … with 24 more rows
##
## $det_threshold_scores
## # A tibble: 170 x 40
## mname leadtime threshold num_cases_for_t… num_cases_for_t… num_cases_for_t…
## <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 AROM… 0 2.5 461 418 421
## 2 AROM… 3 2.5 482 418 436
## 3 AROM… 6 2.5 410 348 358
## 4 AROM… 9 2.5 449 365 403
## 5 AROM… 12 2.5 410 328 363
## 6 AROM… 15 2.5 459 358 422
## 7 AROM… 18 2.5 437 338 389
## 8 AROM… 21 2.5 497 374 466
## 9 AROM… 24 2.5 452 348 413
## 10 AROM… 27 2.5 496 374 471
## # … with 160 more rows, and 34 more variables: cont_tab <list>,
## # threat_score <dbl>, hit_rate <dbl>, miss_rate <dbl>,
## # false_alarm_rate <dbl>, false_alarm_ratio <dbl>, heidke_skill_score <dbl>,
## # pierce_skill_score <dbl>, kuiper_skill_score <dbl>, percent_correct <dbl>,
## # frequency_bias <dbl>, equitable_threat_score <dbl>, odds_ratio <dbl>,
## # log_odds_ratio <dbl>, odds_ratio_skill_score <dbl>,
## # extreme_dependency_score <dbl>, symmetric_eds <dbl>,
## # extreme_dependency_index <dbl>, symmetric_edi <dbl>,
## # threat_score_std_error <dbl>, hit_rate_std_error <dbl>,
## # false_alarm_rate_std_error <dbl>, false_alarm_ratio_std_error <dbl>,
## # heidke_skill_score_std_error <dbl>, pierce_skill_score_std_error <dbl>,
## # percent_correct_std_error <dbl>, equitable_threat_score_std_error <dbl>,
## # log_odds_ratio_std_error <dbl>, log_odds_ratio_degrees_of_freedom <dbl>,
## # odds_ratio_skill_score_std_error <dbl>,
## # extreme_dependency_score_std_error <dbl>, symmetric_eds_std_error <dbl>,
## # extreme_dependency_index_std_error <dbl>, symmetric_edi_std_error <dbl>
##
## attr(,"parameter")
## [1] "S10m"
## attr(,"start_date")
## [1] "2019021700"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 828As you can see, a very large number of scores are computed. harp has a function for plotting point verification scores, plot_point_verif. For summary scores, you just need to give it the verification data and tell it which score you’d like to plot, as well as tell the function that it is deterministic verification data.
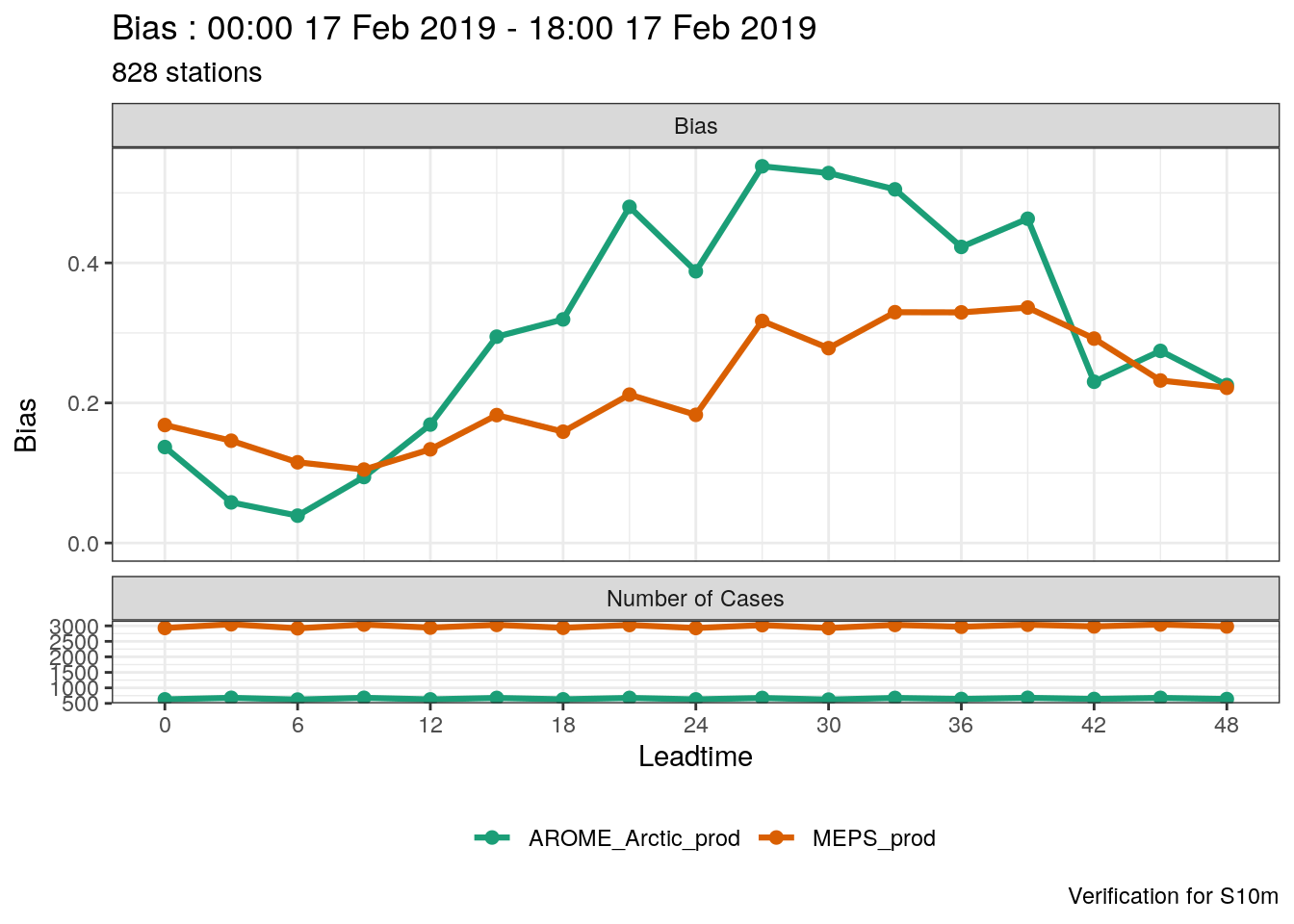
One thing you’ll immediately notice is that the number of cases for MEPS_prod is much larger than for AROME_Arctic_prod. This means that in this verification we are not making a fair comparison - we should actually only be verifying the dates and locations that are common to both systems. harp provides the function common_cases() to do just that!
## ● AROME_Arctic_prod
## # A tibble: 10,170 x 13
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1036 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1037 S10m
## # … with 10,160 more rows, and 8 more variables: AROME_Arctic_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, S10m <dbl>
##
## ● MEPS_prod
## # A tibble: 10,170 x 13
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1036 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1037 S10m
## # … with 10,160 more rows, and 8 more variables: MEPS_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, S10m <dbl>You will see that now both AROME_Arctic_prod and MEPS_prod have the exact same number of rows in their data. Now if we run the verfication again and plot the same score we will see that both forecasting systems have the same number of cases.
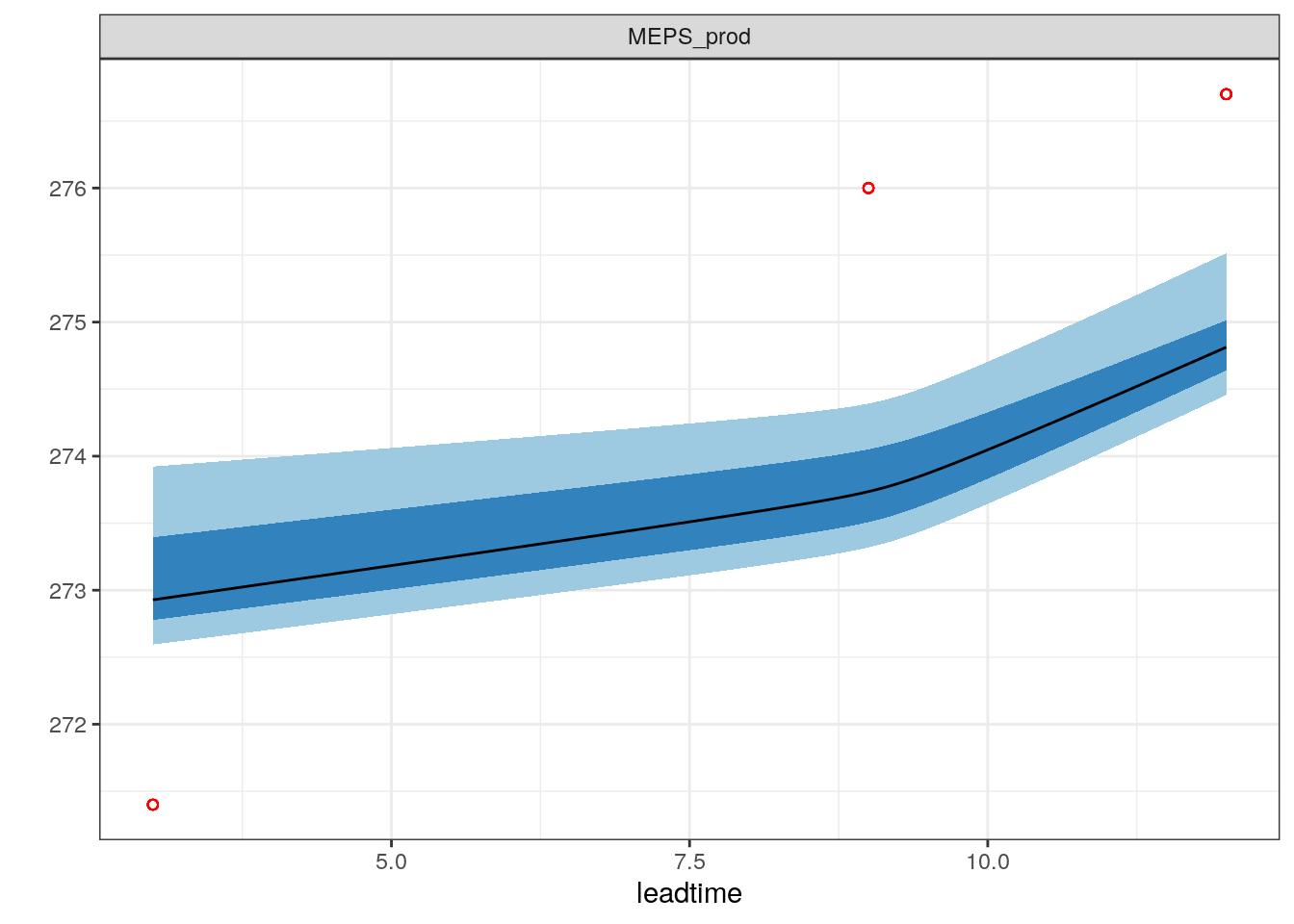
verif_s10m <- det_verify(s10m, S10m, thresholds = seq(2.5, 12.5, 2.5))
plot_point_verif(verif_s10m, bias, verif_type = "det")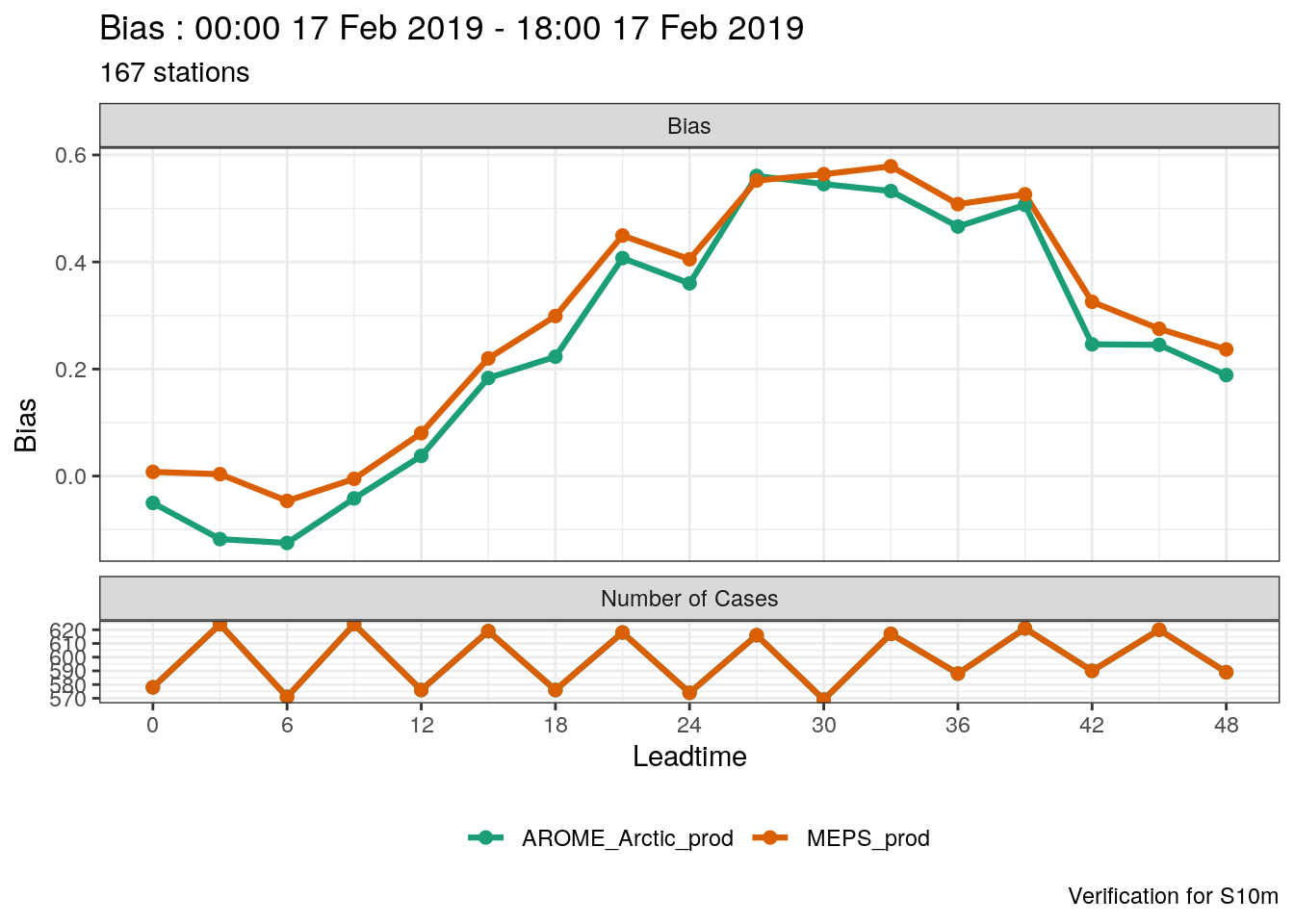
Your turn:
- Try plotting one of the threshold scores (frequency_bias, for example). Try to figure out wht the plot looks so weird
Solution:
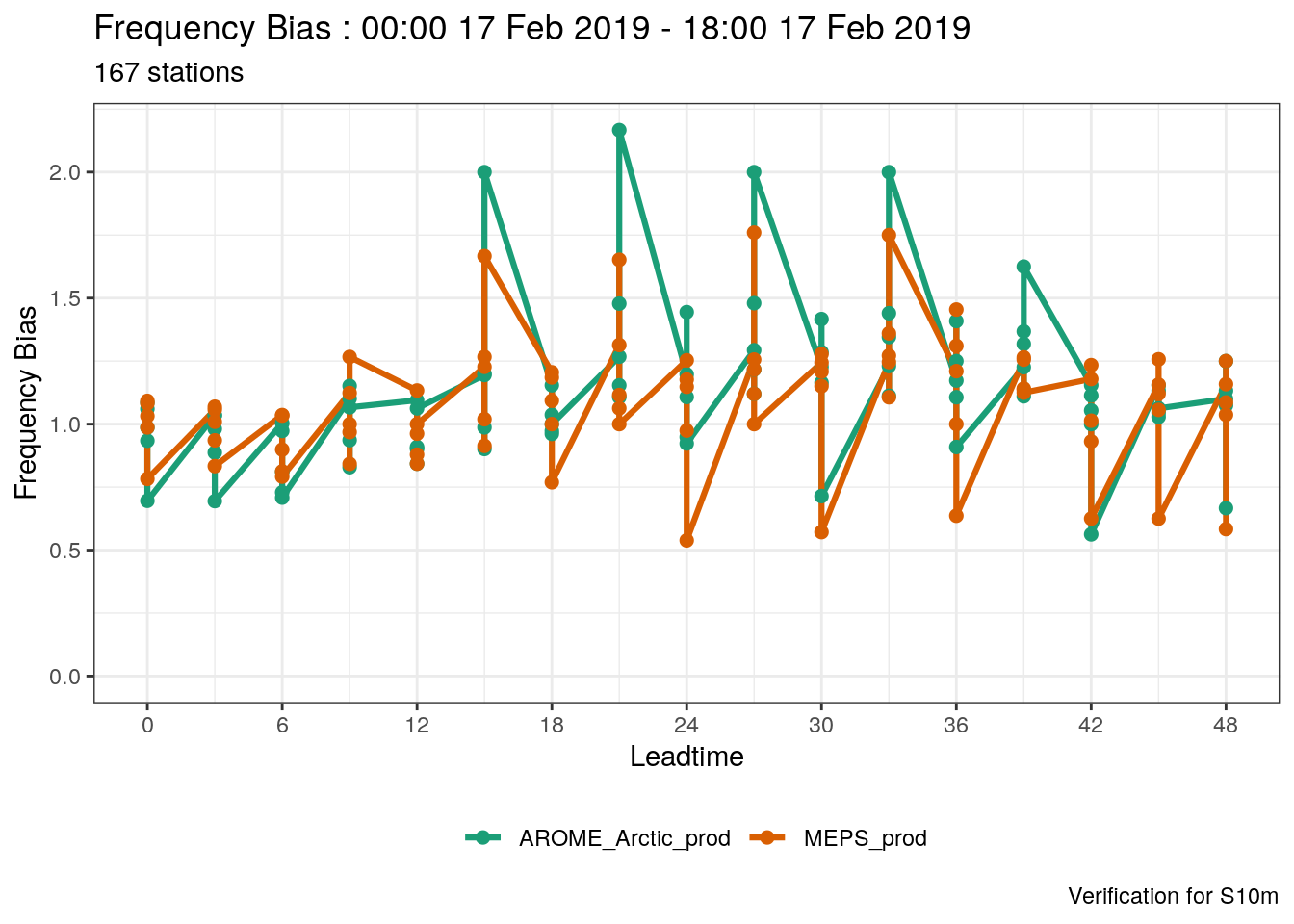
The plot looks weird becasue it’s attempting to plot scores for all thresholds at the same time.
When we have more than one threshold, we need to tell plot_point_verif what to do - there are 2 options - to facet or to filter, with the arguments facet_by or filter_by. These arguments work in pretty much the same way as facet_wrap. For example if we wanted the facet the scores by threshold, we would do
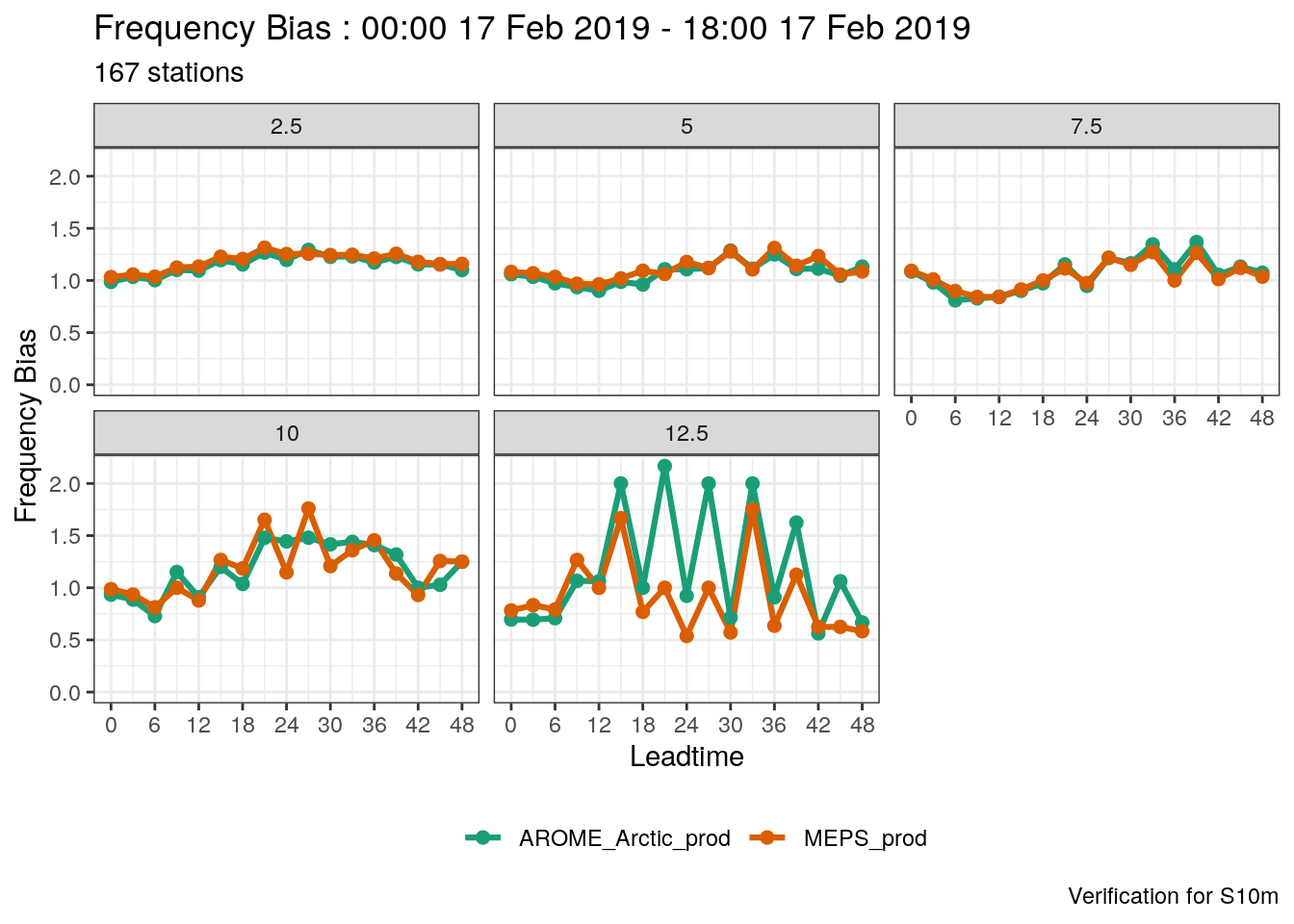
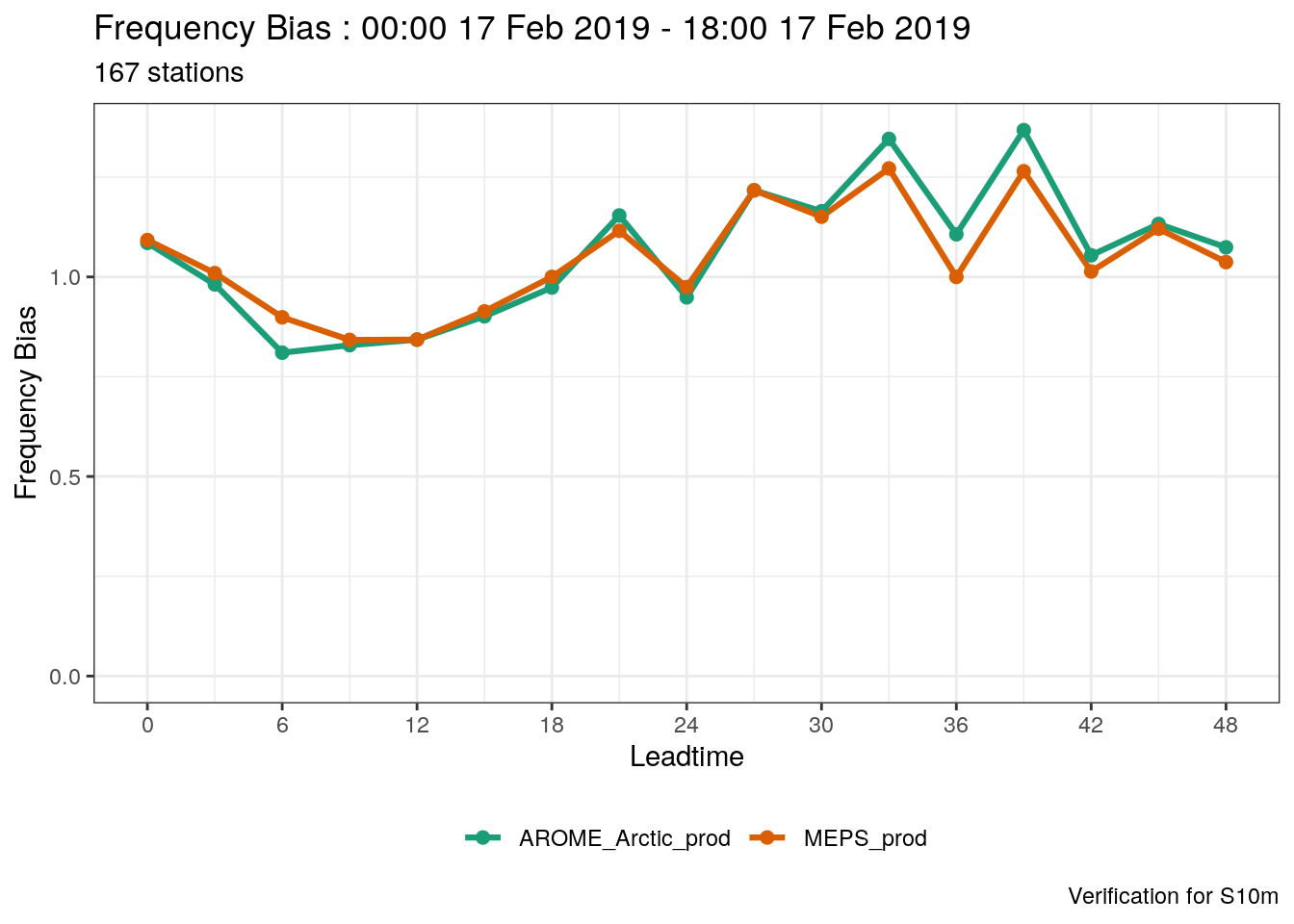
Or, if we just wanted the plot for a threshold of 7.5 ms-1, we would use filter_by
plot_point_verif(
verif_s10m,
frequency_bias,
verif_type = "det",
filter_by = vars(threshold == 7.5)
) 
4.2.2 Verification by group
The default behaviour of harp verification functions is to compute the verification metrics for each lead time. However, you can also compute the scores for any groups of data, much in the same way as group_by enables you to do. In this case groups are specified in the groupings argument to the verification function, and unlike group_by the column names you wish to use for grouping variables must be quoted (this may change in the future for consistency with group_by) and if there are more than one in a charcater vector. We could for example compute scores for each valid time:
## $det_summary_scores
## # A tibble: 46 x 7
## mname validdate num_cases bias rmse mae stde
## <chr> <dttm> <int> <dbl> <dbl> <dbl> <dbl>
## 1 AROME_Arctic_prod 2019-02-17 00:00:00 147 0.276 3.04 2.28 3.04
## 2 AROME_Arctic_prod 2019-02-17 03:00:00 155 0.121 2.90 2.11 2.91
## 3 AROME_Arctic_prod 2019-02-17 06:00:00 270 0.0203 2.68 1.81 2.68
## 4 AROME_Arctic_prod 2019-02-17 09:00:00 312 -0.295 1.95 1.35 1.93
## 5 AROME_Arctic_prod 2019-02-17 12:00:00 459 -0.235 2.07 1.44 2.06
## 6 AROME_Arctic_prod 2019-02-17 15:00:00 468 -0.112 1.95 1.26 1.95
## 7 AROME_Arctic_prod 2019-02-17 18:00:00 572 -0.0128 1.84 1.30 1.84
## 8 AROME_Arctic_prod 2019-02-17 21:00:00 628 0.192 2.05 1.39 2.05
## 9 AROME_Arctic_prod 2019-02-18 00:00:00 560 -0.0470 2.25 1.53 2.25
## 10 AROME_Arctic_prod 2019-02-18 03:00:00 620 0.126 2.04 1.45 2.03
## # … with 36 more rows
##
## $det_threshold_scores
## # A tibble: 0 x 0
##
## attr(,"parameter")
## [1] "S10m"
## attr(,"start_date")
## [1] "2019021700"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 167To plot the score, we then need to tell plot_point_verif to use validdate as the x-axis (the default is lead time)
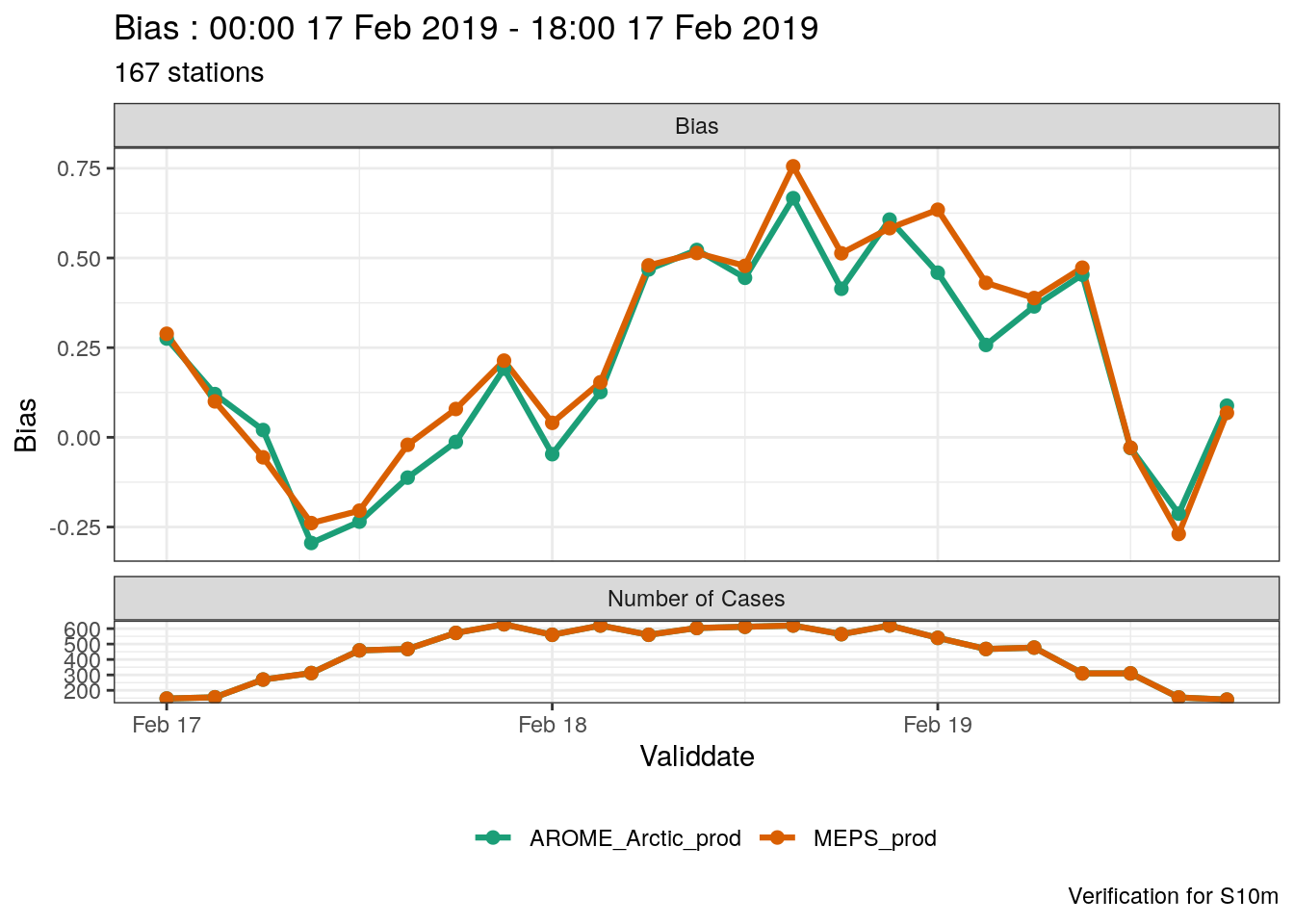
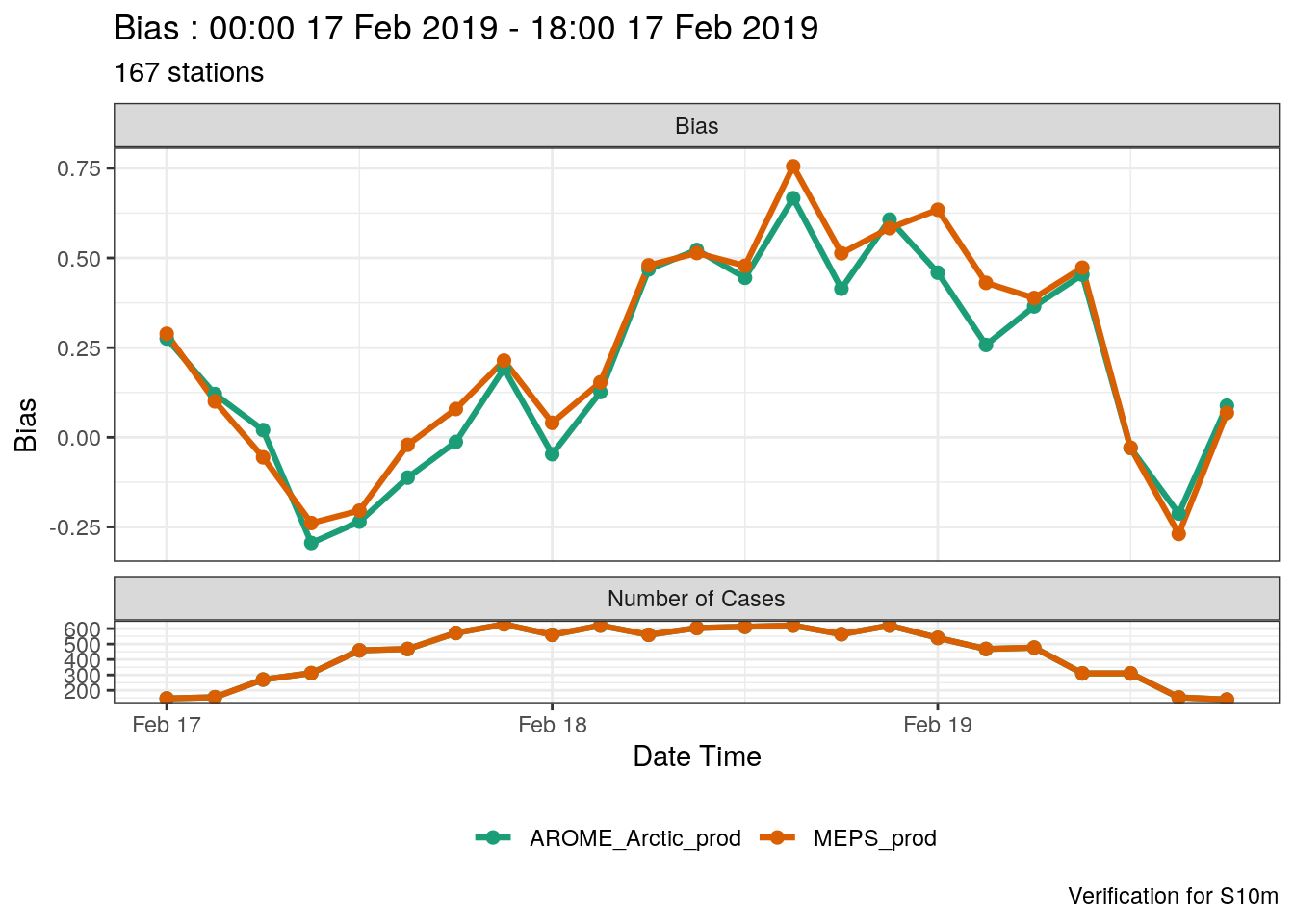
If you want to change the date into a readable format, you can use the mutate_list function.
plot_point_verif(
mutate_list(verif_s10m, date_time = unix2datetime(validdate)),
bias,
x_axis = date_time
)
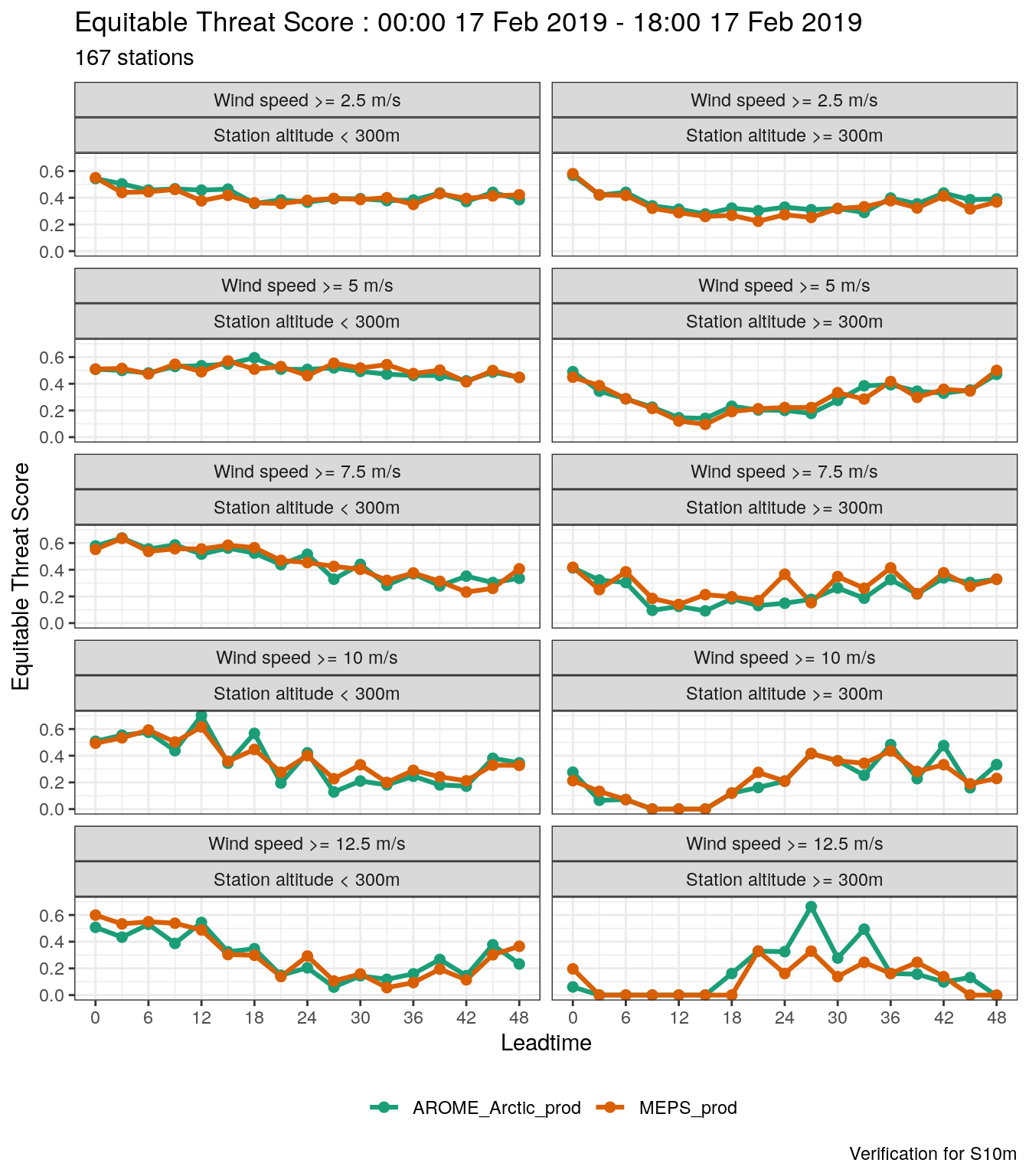
Your turn:
- Compute verification scores for stations with elevations \(\geqslant 300 m\) and those \(\lt 300 m\). for each lead time and thresholds of 2.5 - 12.5 ms-1 every 2.5 ms-1. To classify the station heights, you can use
stations <- mutate(
station_list,
station_height = cut(elev, breaks = c(-Inf, 300, Inf), labels = c("< 300m", ">= 300m"))
)
s10m <- join_to_fcst(s10m, stations, force_join = TRUE)- Plot the equitable threat score for each threshold and station height group.
Solutions
- Compute verification scores for stations with elevations \(\geqslant 300 m\) and those \(\lt 300 m\). for each lead time and thresholds of 2.5 - 12.5 ms-1 every 2.5 ms-1.
stations <- mutate(
station_list,
station_height = cut(elev, breaks = c(-Inf, 300, Inf), labels = c("< 300m", ">= 300m"))
)
(verif_s10m <- join_to_fcst(s10m, stations, force_join = TRUE) %>%
det_verify(S10m, groupings = c("leadtime", "station_height"), thresholds = seq(2.5, 12.5, 2.5)))## $det_summary_scores
## # A tibble: 68 x 8
## mname leadtime station_height num_cases bias rmse mae stde
## <chr> <int> <fct> <int> <dbl> <dbl> <dbl> <dbl>
## 1 AROME_Arctic_prod 0 < 300m 410 0.200 2.08 1.56 2.08
## 2 AROME_Arctic_prod 0 >= 300m 168 -0.661 3.16 2.04 3.10
## 3 AROME_Arctic_prod 3 < 300m 455 0.111 1.82 1.36 1.82
## 4 AROME_Arctic_prod 3 >= 300m 169 -0.734 3.04 1.89 2.96
## 5 AROME_Arctic_prod 6 < 300m 403 0.117 1.88 1.42 1.88
## 6 AROME_Arctic_prod 6 >= 300m 168 -0.704 2.86 1.78 2.78
## 7 AROME_Arctic_prod 9 < 300m 454 0.126 1.62 1.18 1.62
## 8 AROME_Arctic_prod 9 >= 300m 170 -0.490 2.54 1.61 2.50
## 9 AROME_Arctic_prod 12 < 300m 406 0.234 1.80 1.31 1.79
## 10 AROME_Arctic_prod 12 >= 300m 170 -0.430 2.70 1.68 2.68
## # … with 58 more rows
##
## $det_threshold_scores
## # A tibble: 340 x 41
## mname leadtime station_height threshold num_cases_for_t… num_cases_for_t…
## <chr> <int> <fct> <dbl> <dbl> <dbl>
## 1 AROM… 0 < 300m 2.5 308 281
## 2 AROM… 0 >= 300m 2.5 102 94
## 3 AROM… 3 < 300m 2.5 316 275
## 4 AROM… 3 >= 300m 2.5 111 93
## 5 AROM… 6 < 300m 2.5 271 231
## 6 AROM… 6 >= 300m 2.5 88 75
## 7 AROM… 9 < 300m 2.5 289 236
## 8 AROM… 9 >= 300m 2.5 105 80
## 9 AROM… 12 < 300m 2.5 260 214
## 10 AROM… 12 >= 300m 2.5 98 71
## # … with 330 more rows, and 35 more variables:
## # num_cases_for_threshold_forecast <dbl>, cont_tab <list>,
## # threat_score <dbl>, hit_rate <dbl>, miss_rate <dbl>,
## # false_alarm_rate <dbl>, false_alarm_ratio <dbl>, heidke_skill_score <dbl>,
## # pierce_skill_score <dbl>, kuiper_skill_score <dbl>, percent_correct <dbl>,
## # frequency_bias <dbl>, equitable_threat_score <dbl>, odds_ratio <dbl>,
## # log_odds_ratio <dbl>, odds_ratio_skill_score <dbl>,
## # extreme_dependency_score <dbl>, symmetric_eds <dbl>,
## # extreme_dependency_index <dbl>, symmetric_edi <dbl>,
## # threat_score_std_error <dbl>, hit_rate_std_error <dbl>,
## # false_alarm_rate_std_error <dbl>, false_alarm_ratio_std_error <dbl>,
## # heidke_skill_score_std_error <dbl>, pierce_skill_score_std_error <dbl>,
## # percent_correct_std_error <dbl>, equitable_threat_score_std_error <dbl>,
## # log_odds_ratio_std_error <dbl>, log_odds_ratio_degrees_of_freedom <dbl>,
## # odds_ratio_skill_score_std_error <dbl>,
## # extreme_dependency_score_std_error <dbl>, symmetric_eds_std_error <dbl>,
## # extreme_dependency_index_std_error <dbl>, symmetric_edi_std_error <dbl>
##
## attr(,"parameter")
## [1] "S10m"
## attr(,"start_date")
## [1] "2019021700"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 167- Plot the equitable threat score for each threshold and station height group.
plot_point_verif(
mutate_list(
verif_s10m,
threshold = paste("Wind speed >=", threshold, "m/s"),
station_height = paste("Station altitude", station_height)
),
equitable_threat_score,
facet_by = vars(fct_inorder(threshold), station_height),
num_facet_cols = 2
)
Bearing in mind the plot_point_verif uses ggplot, you could also do the faceting yourself and have more control - for example, you coud use facet_grid
plot_point_verif(
mutate_list(
verif_s10m,
threshold = paste("S10m >=", threshold, "m/s"),
station_height = paste("Station altitude", station_height)
),
equitable_threat_score
) +
facet_grid(cols = vars(station_height), rows = vars(fct_inorder(threshold)))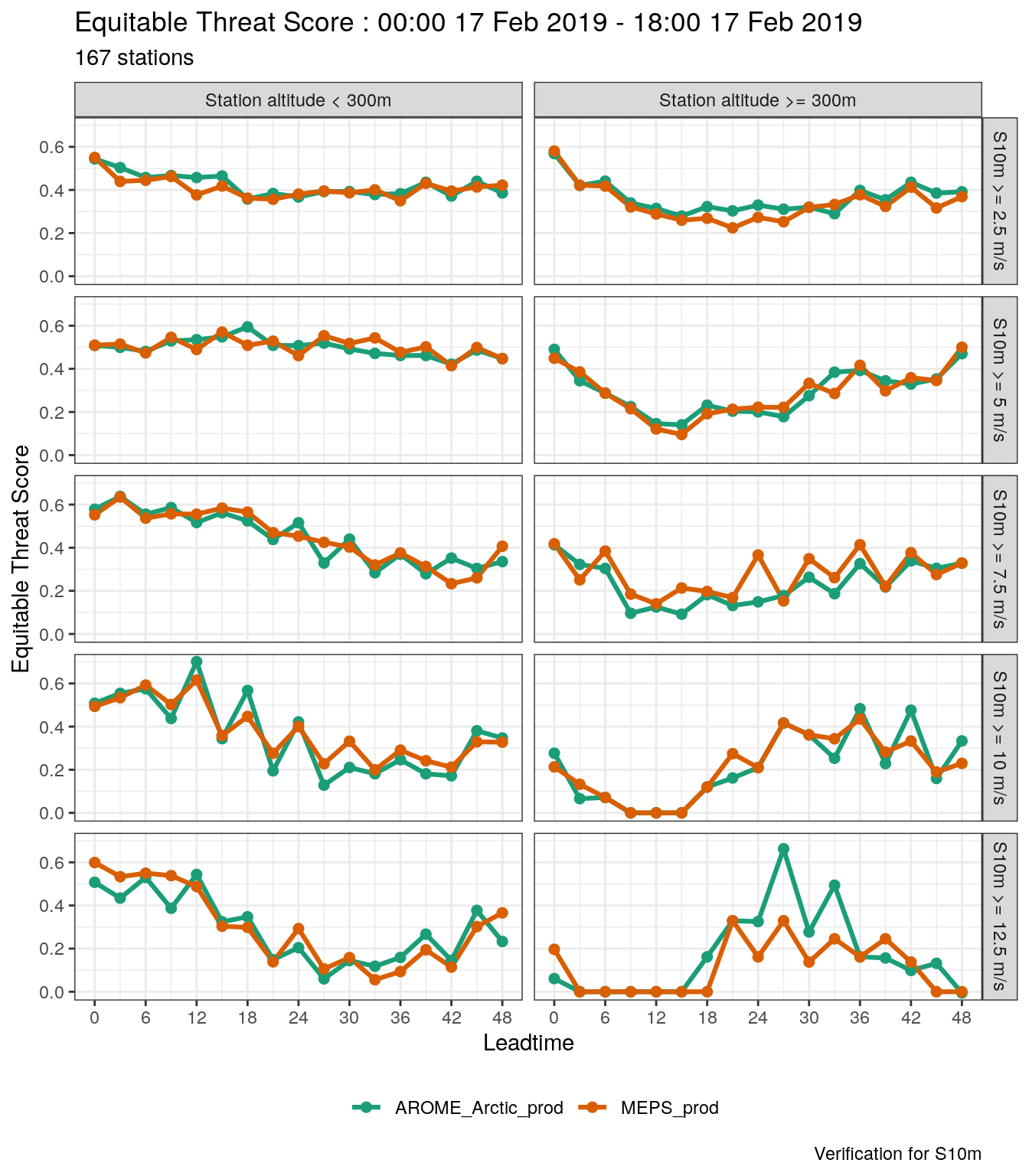
4.2.3 Vertical profiles
When we converted our data to sqlite, we also converted some upper air data for temperature and dew point temperature. To read in upper air data, we need to tell read_point_forecast and read_point_obs what the vertical coordinate is.
(t_upper <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = c("AROME_Arctic_prod", "MEPS_prod"),
fcst_type = "det",
parameter = "T",
file_path = here("data/FCTABLE/deterministic"),
vertical_coordinate = "pressure"
))## ● AROME_Arctic_prod
## # A tibble: 6,967 x 10
## fcdate validdate leadtime SID parameter p
## <dttm> <dttm> <int> <int> <chr> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 50
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 100
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 150
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 200
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 250
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 300
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 400
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 500
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 700
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 850
## # … with 6,957 more rows, and 4 more variables: AROME_Arctic_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>
##
## ● MEPS_prod
## # A tibble: 29,956 x 10
## fcdate validdate leadtime SID parameter p
## <dttm> <dttm> <int> <int> <chr> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 50
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 100
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 150
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 200
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 250
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 300
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 400
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 500
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 700
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T 850
## # … with 29,946 more rows, and 4 more variables: MEPS_prod_det <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>td_upper <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = c("AROME_Arctic_prod", "MEPS_prod"),
fcst_type = "det",
parameter = "Td",
file_path = here("data/FCTABLE/deterministic"),
vertical_coordinate = "pressure"
)harp has a function for plotting vertical profile, that allows you compare the profiles from different models - but only for the same parameter.
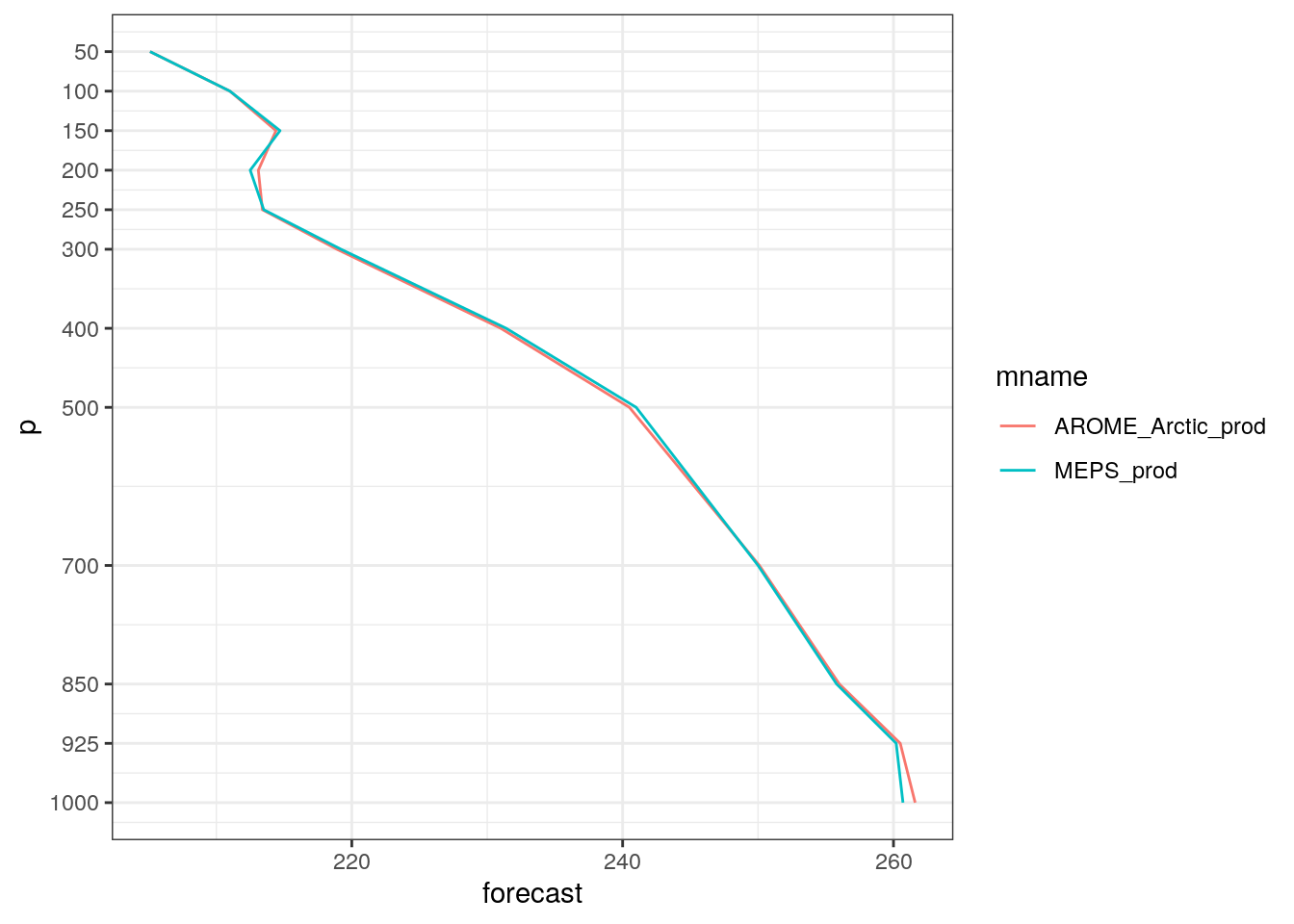
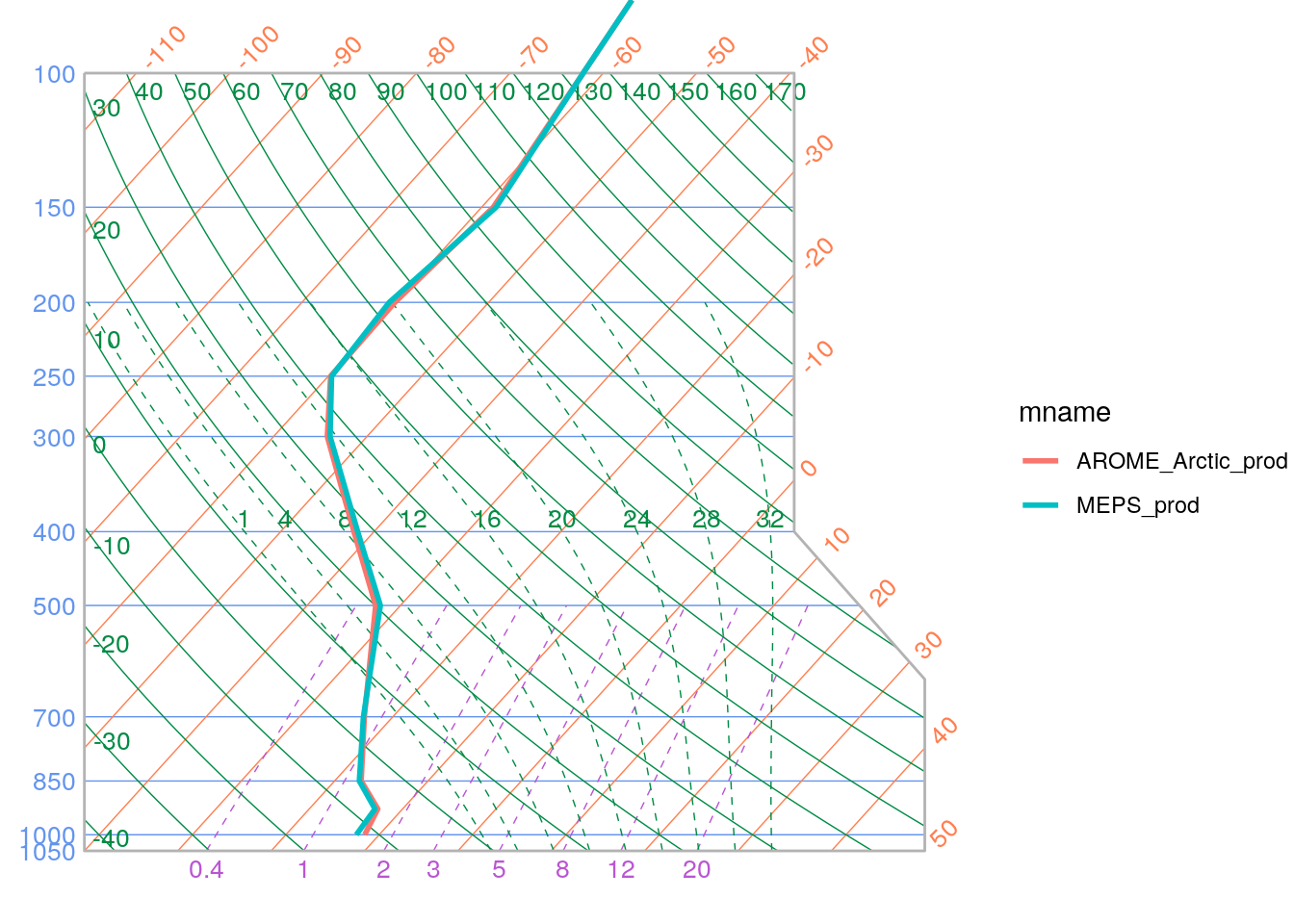
You can also plot the profiles on skew-t / log P grid by setting skew_t = TRUE. However, it should be noted that temperatures need to be in °C rather than Kelvin. We can convert the units by using scale_point_forecast.
scale_point_forecast(t_upper, -273.15, new_units = "degC") %>%
plot_vertical_profile(
SID = 22113,
fcdate = 2019021712,
lead_time = 24,
skew_t = TRUE
)
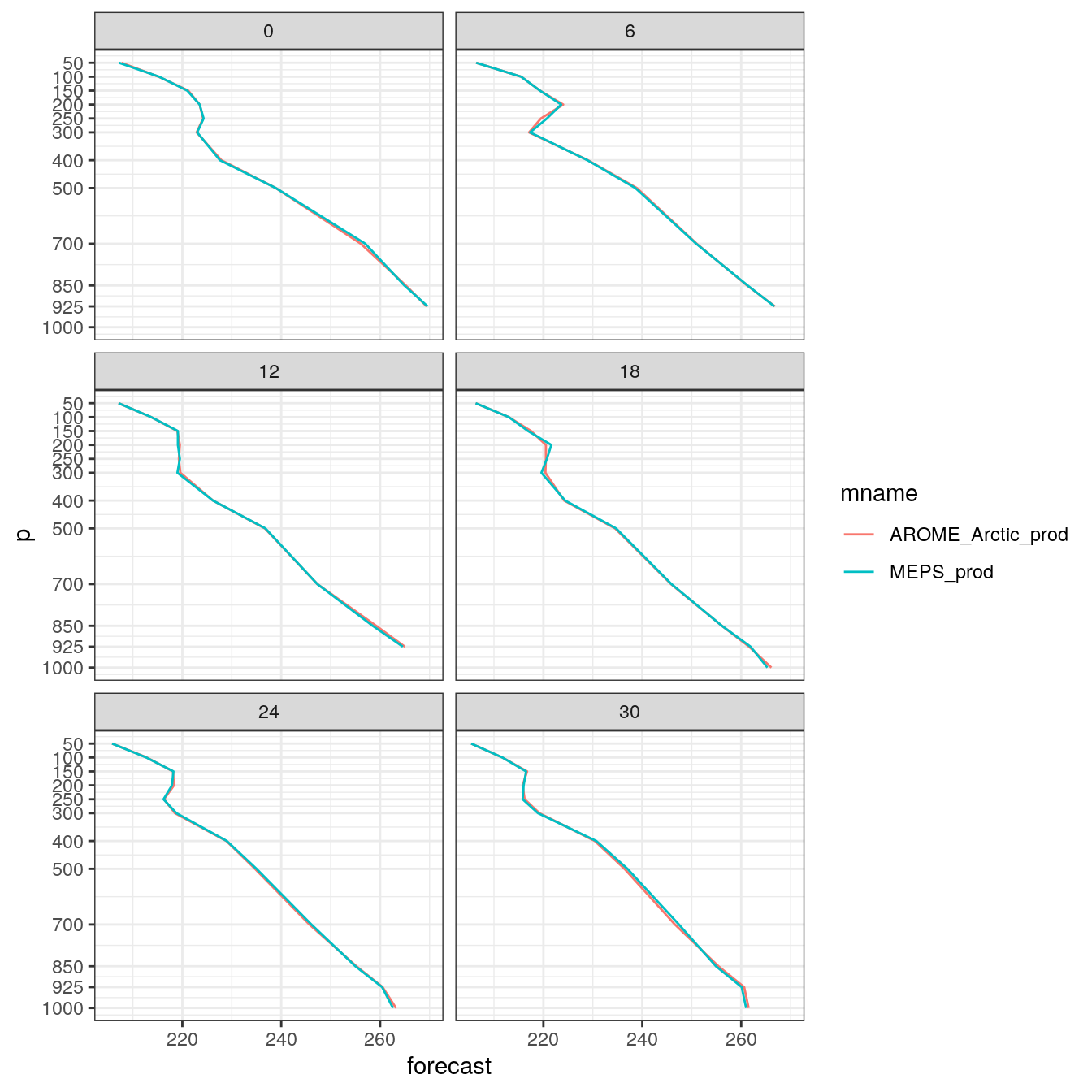
Your turn:
- You can specify more than 1 station, date, and / or lead time in
plot_vertical_profile. Experiment with making some multi panel plots. - Can you figure out how you would add the dew point temperature to the plots?
Solution
- Experiment with making some multi panel plots.
plot_vertical_profile(
t_upper,
SID = 22113,
fcdate = 2019021700,
lead_time = seq(0, 30, 6),
facet_by = vars(leadtime)
)
- Can you figure out how you would add the dew point temperature to the plots?
plot_vertical_profile(
t_upper,
SID = 22113,
fcdate = 2019021712,
lead_time = 24
) +
geom_path(
data = filter(
bind_fcst(td_upper),
SID == 22113,
fcdate == str_datetime_to_unixtime(2019021712),
leadtime == 24
),
aes(linetype = "Dew Point")
) +
scale_linetype_manual("", values = 2)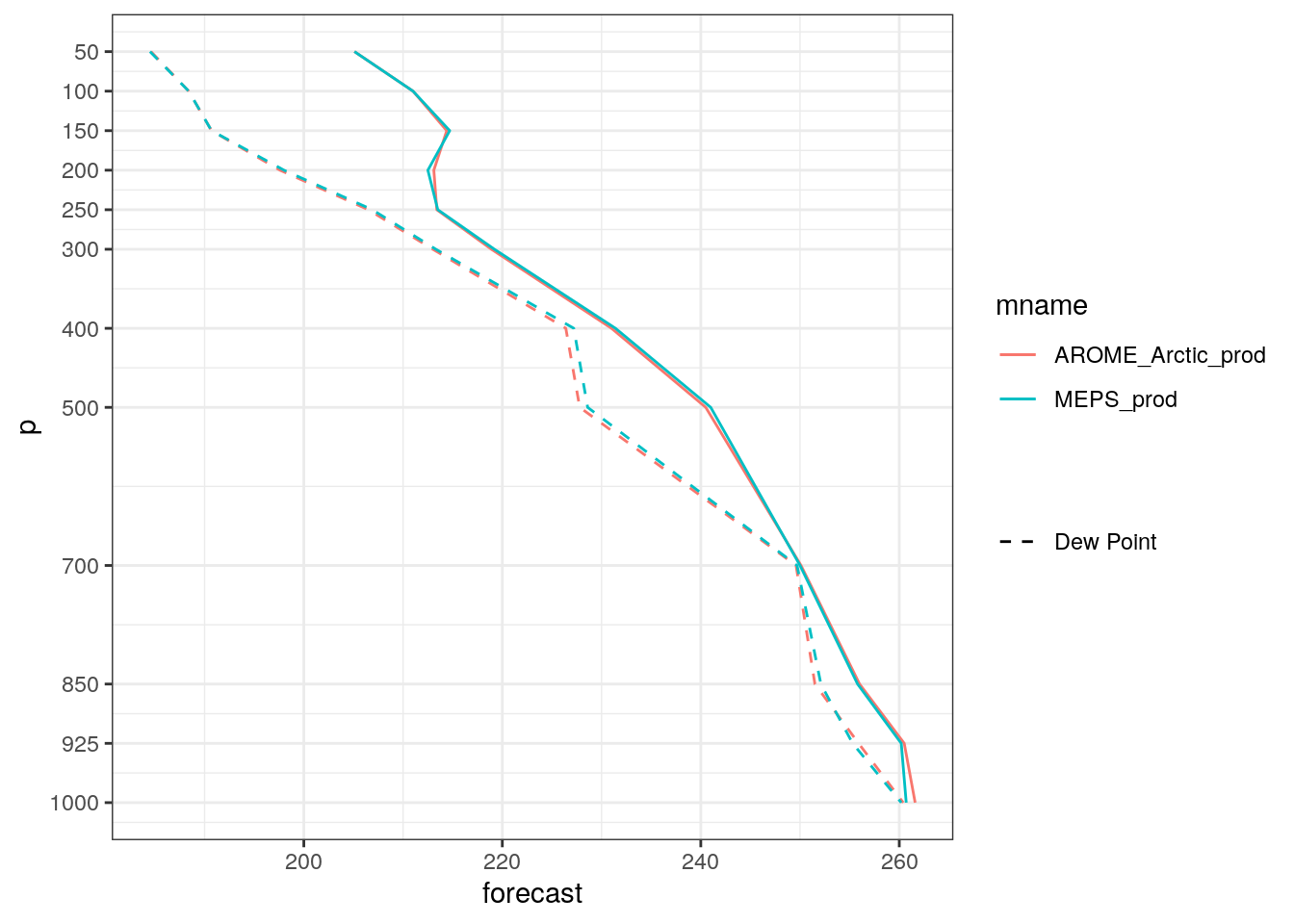
4.3 Reading in ensemble data
Now we have seen harp in action with deterministic data, let’s move on to ensemble data. harp’s origins are in verification of ensemble data, so the functionality here is a little more mature. Many of the same functions that were introduced in the deterministic section can be used for ensemble data as well. There are also functions that currently only work with ensemble data and are in the process of being upgraded to handle deterministic forecasts as well.
We can use the same read_point_forecast function to read in ensemble data - we just need to tell it that we are reading ensemble data by setting fcst_type = "eps".
library(tidyverse)
library(here)
library(harp)
(t2m <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = "MEPS_prod",
fcst_type = "EPS",
parameter = "T2m",
lead_time = seq(0, 12, 3),
by = "6h",
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads"
))## ● MEPS_prod
## # A tibble: 22,980 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 22,970 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>You will see that each ensemble member gets its own column in the data frame. This isn’t really tidy data - for the data to be tidy, the ensemble member would be a variable as well. However, when ensembles become large the slightly untidy format is advantageous - firstly, many of the verification functions we use expect the ensemble data as a matrix and continual pivoting slows these function down a lot and secondly, this format takes up less space in memory. We can, however, convert the data to a tidy format with the function gather_members()
## ● MEPS_prod
## # A tibble: 229,800 x 11
## member fcdate validdate leadtime SID parameter
## * <chr> <dttm> <dttm> <int> <int> <chr>
## 1 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 mbr000 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 229,790 more rows, and 5 more variables: fcst_cycle <chr>,
## # model_elevation <dbl>, units <chr>, forecast <dbl>, sub_model <chr>With the members gathered together we can use bind_fcst in order to make basic plots from the data using ggplot.
bind_fcst(t2m) %>%
filter(SID == 1492, fcdate == str_datetime_to_unixtime(2019021712)) %>%
ggplot(aes(x = unix2datetime(validdate), y = forecast, colour = member)) +
geom_line()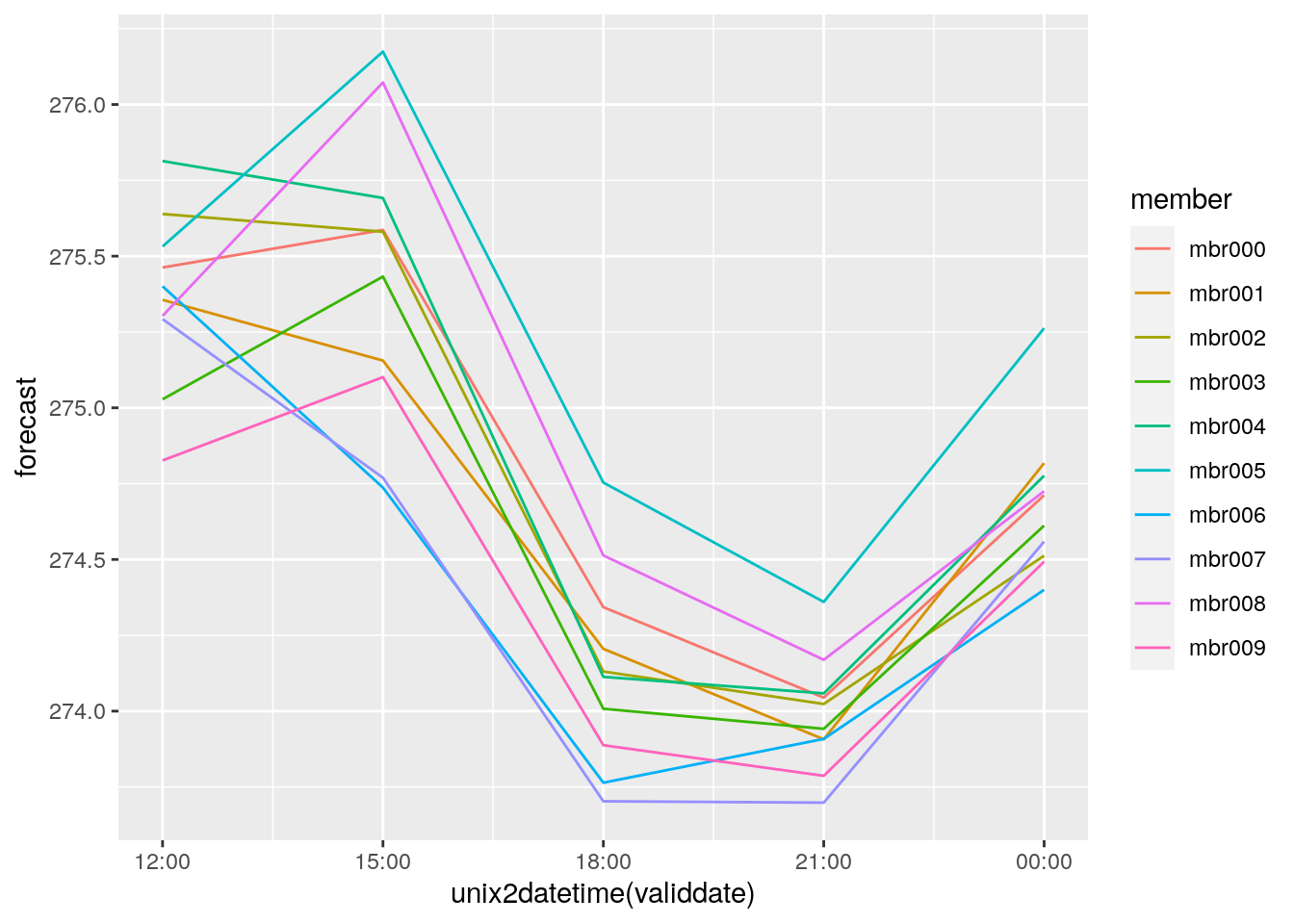
bind_fcst(t2m) %>%
mutate(leadtime = fct_inorder(paste0("Lead time: ", leadtime, "h"))) %>%
ggplot(aes(forecast, colour = leadtime, fill = leadtime)) +
geom_density(alpha = 0.5) +
facet_wrap(vars(leadtime)) +
theme(legend.position = "none")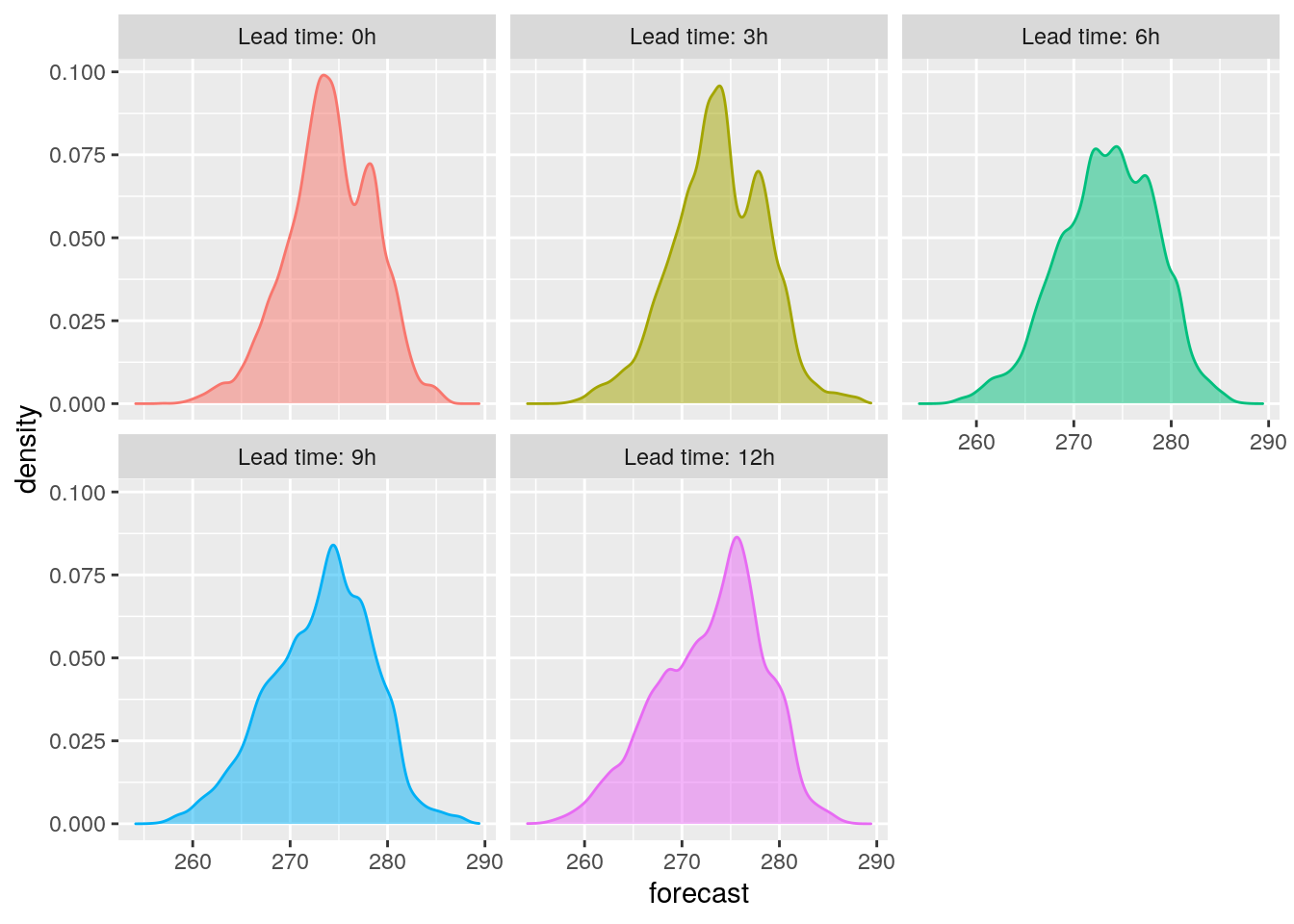
There are also a number of different ways you can plot time series of ensemble forecasts for a station. This can be done with the function plot_station_eps. You give it the harp_fcst object and tell it what station and forecast start time you want the plot for, and optionally what sort of plot you want.
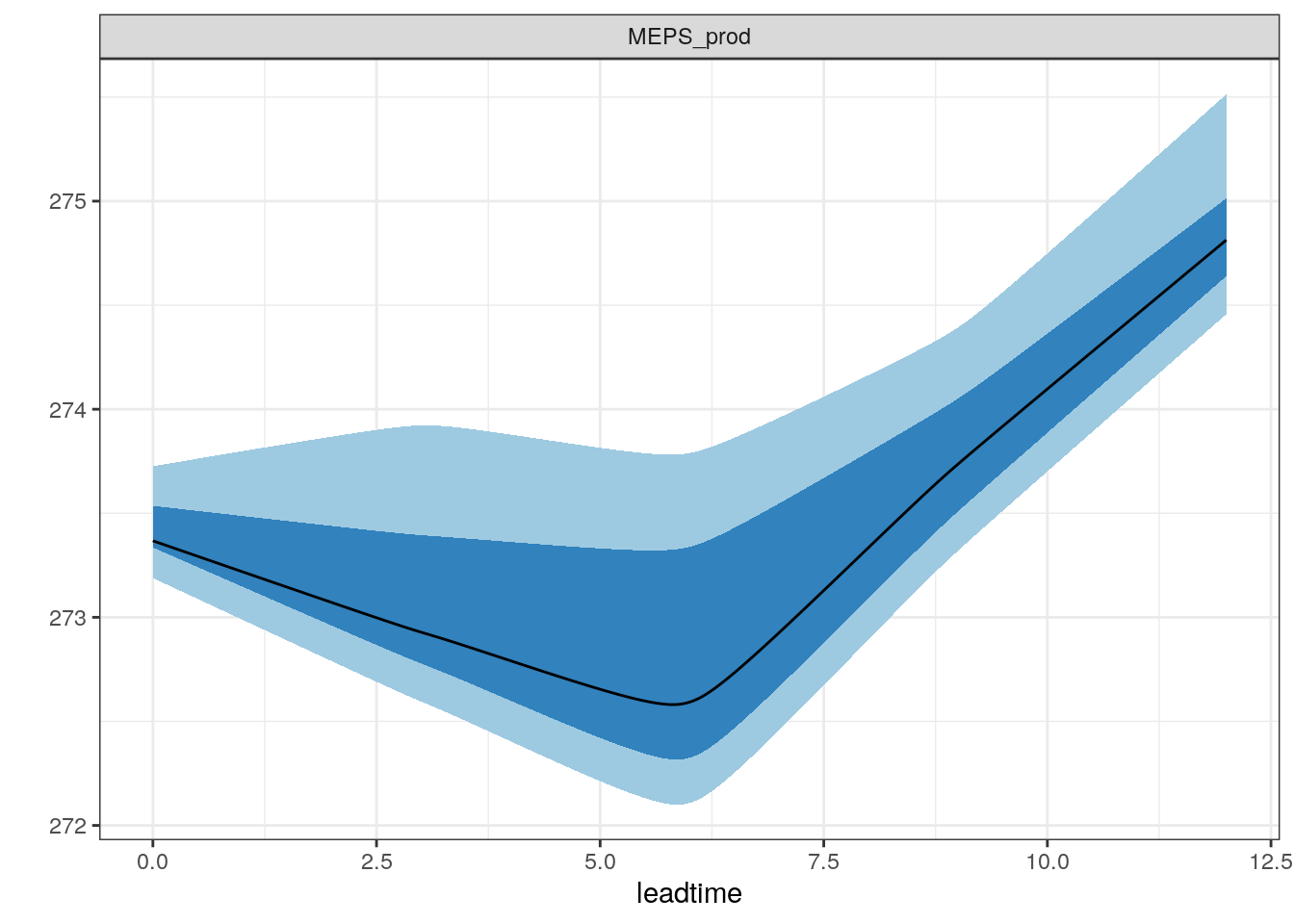
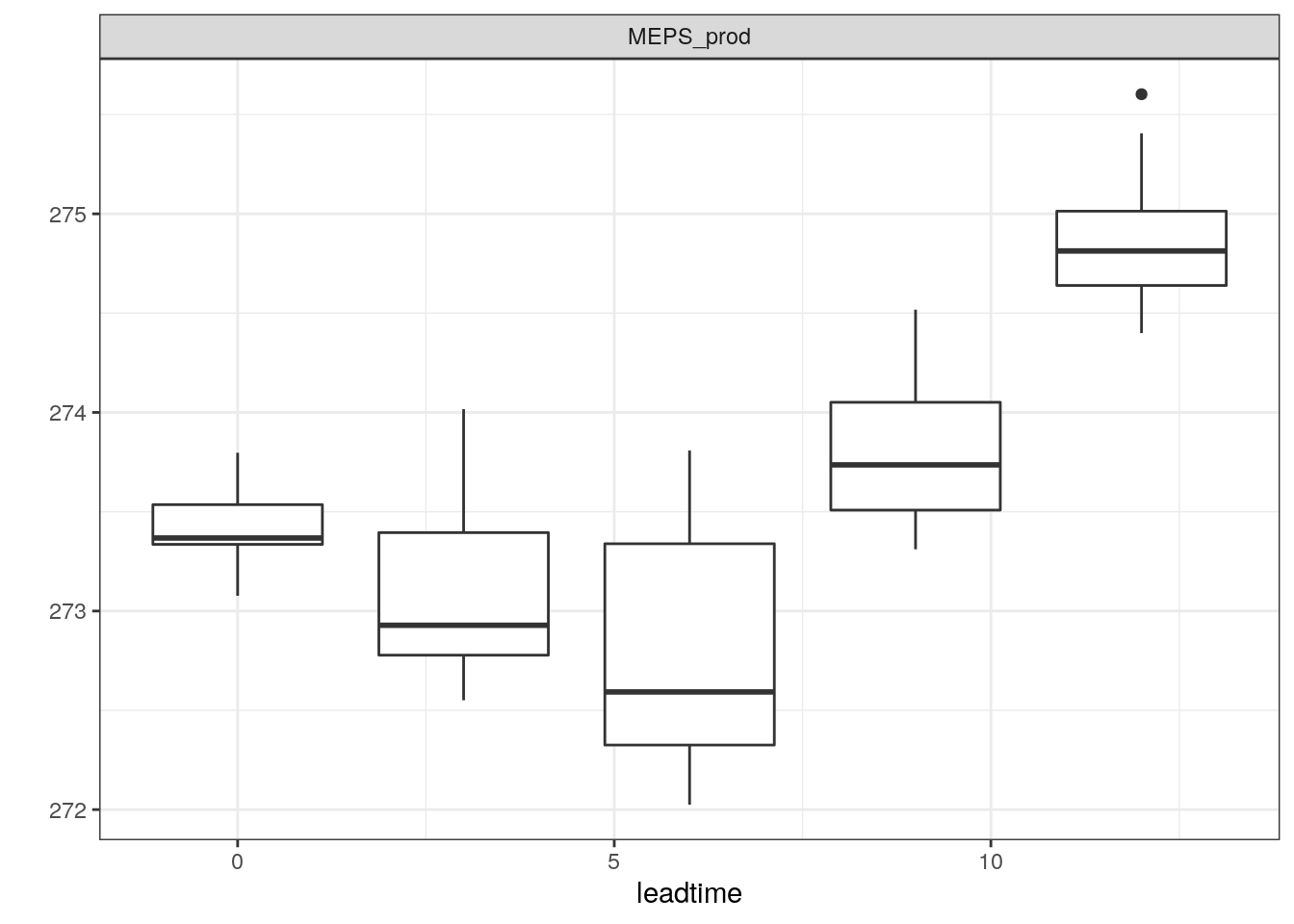
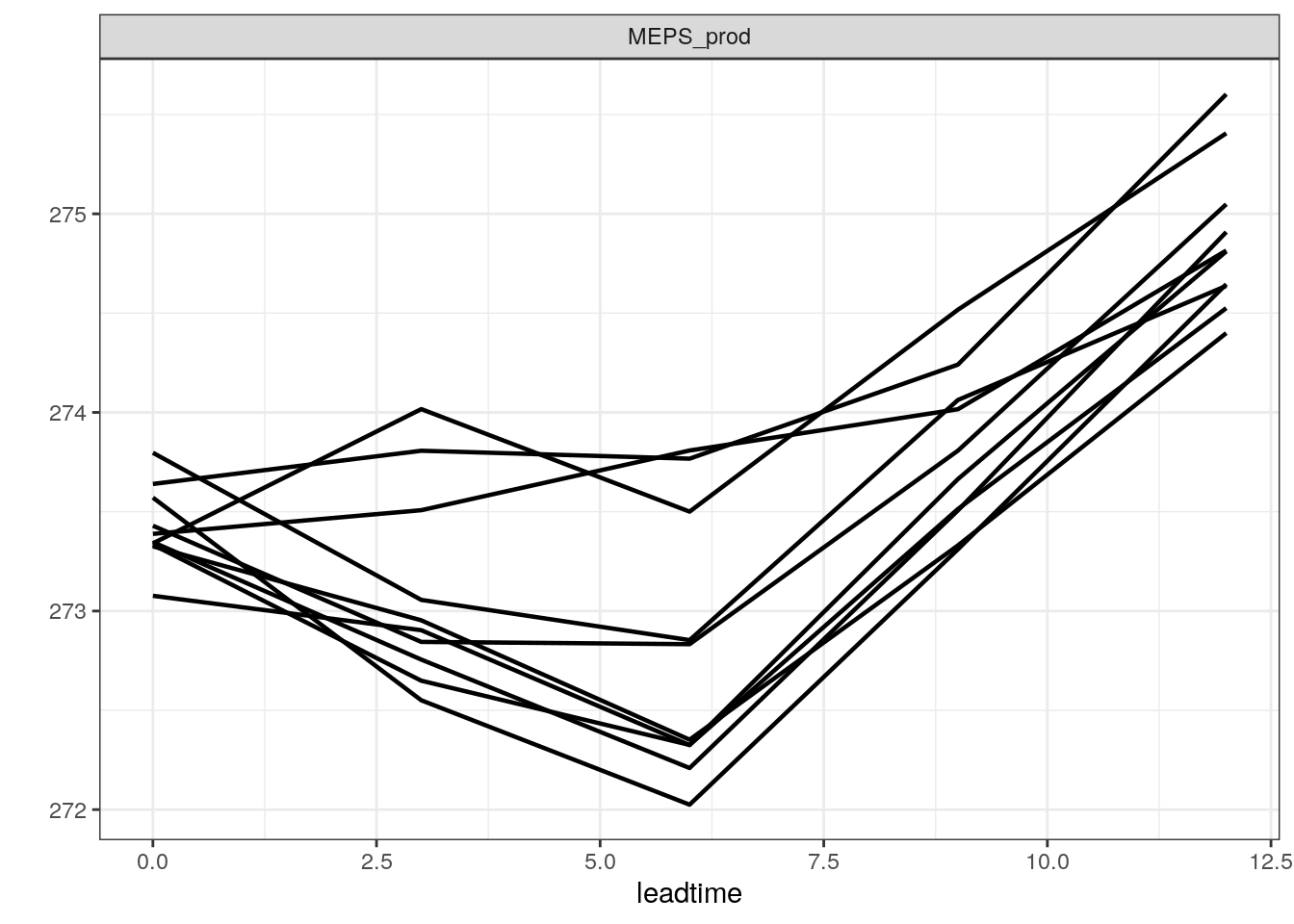
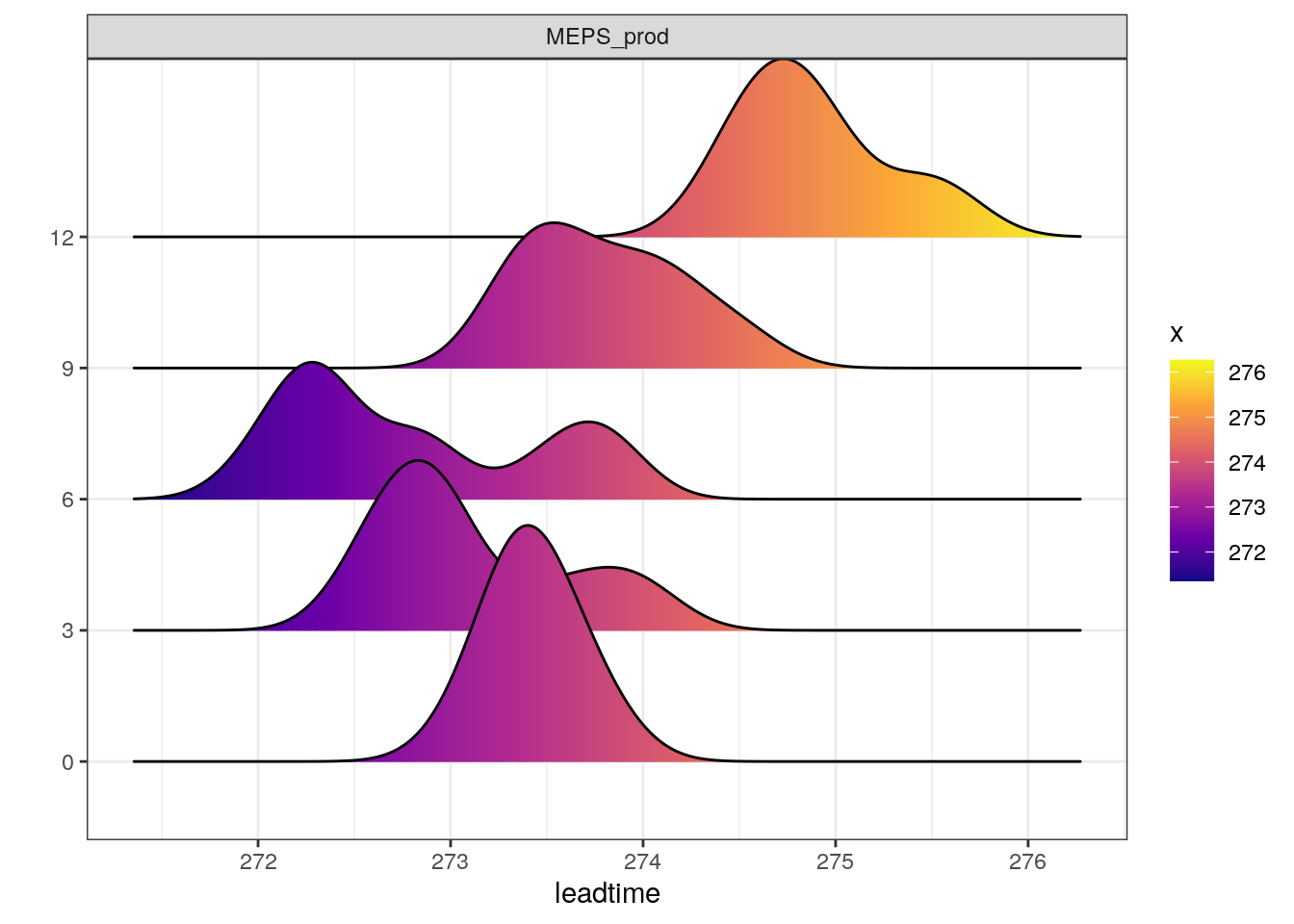
There are other types of plot that are more suited to truncated distributions such as those that are bound at 0 for wind speed and precipitation. When we converted the precipitation data to SQLite, we do not take any accout of accumulation times - the data are as they are output from in the model as accumulation since the model start time. We can do the accumulation when we read in the data using read_point_forecast by prefixing the parameter name with “Acc” for accumulated and suffixing it with the accumulation time in hours, e.g. “6h”.
Your turn:
- Read in 3h accumulated precipitatino from MEPS. Use
show_harp_parameters()if you need some guidance. - Find the time and station with the heighest forecast precipitation, and which forecast it s for.
Solution:
- Read in 3h accumulated precipitatino from MEPS. Use
show_harp_parameters()if you need some guidance.
(precip_3h <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = "MEPS_prod",
fcst_type = "EPS",
parameter = "AccPcp3h",
lead_time = seq(0, 12, 3),
by = "6h",
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads"
))## ● MEPS_prod
## # A tibble: 19,248 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1320 Pcp
## 2 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1043 Pcp
## 3 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1193 Pcp
## 4 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1117 Pcp
## 5 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1112 Pcp
## 6 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1161 Pcp
## 7 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1098 Pcp
## 8 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1162 Pcp
## 9 2019-02-17 00:00:00 2019-02-17 03:00:00 3 3007 Pcp
## 10 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1476 Pcp
## # … with 19,238 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>- Find the time and station with the heighest forecast precipitation
bind_fcst(precip_3h) %>%
group_by(SID, fcdate, validdate) %>%
summarise(max_precip = max(forecast)) %>%
arrange(desc(max_precip)) %>%
ungroup() %>%
mutate(fcdate = unix2datetime(fcdate), validdate = unix2datetime(validdate))## # A tibble: 19,248 x 4
## SID fcdate validdate max_precip
## <int> <dttm> <dttm> <dbl>
## 1 1106 2019-02-17 06:00:00 2019-02-17 09:00:00 10.3
## 2 1107 2019-02-17 06:00:00 2019-02-17 09:00:00 10.3
## 3 1121 2019-02-17 00:00:00 2019-02-17 03:00:00 7.46
## 4 22113 2019-02-17 00:00:00 2019-02-17 06:00:00 6.16
## 5 1611 2019-02-17 00:00:00 2019-02-17 03:00:00 6.13
## 6 1015 2019-02-17 12:00:00 2019-02-17 21:00:00 5.77
## 7 1201 2019-02-17 12:00:00 2019-02-17 21:00:00 5.65
## 8 1611 2019-02-17 18:00:00 2019-02-18 06:00:00 5.64
## 9 1014 2019-02-17 06:00:00 2019-02-17 18:00:00 5.28
## 10 1122 2019-02-17 00:00:00 2019-02-17 03:00:00 5.27
## # … with 19,238 more rowsLet’s plot a time series for that forecast.
plot_station_eps(precip_3h, 1106, 2019021706, type = "boxplot") + scale_x_continuous(breaks = seq(0, 12, 3))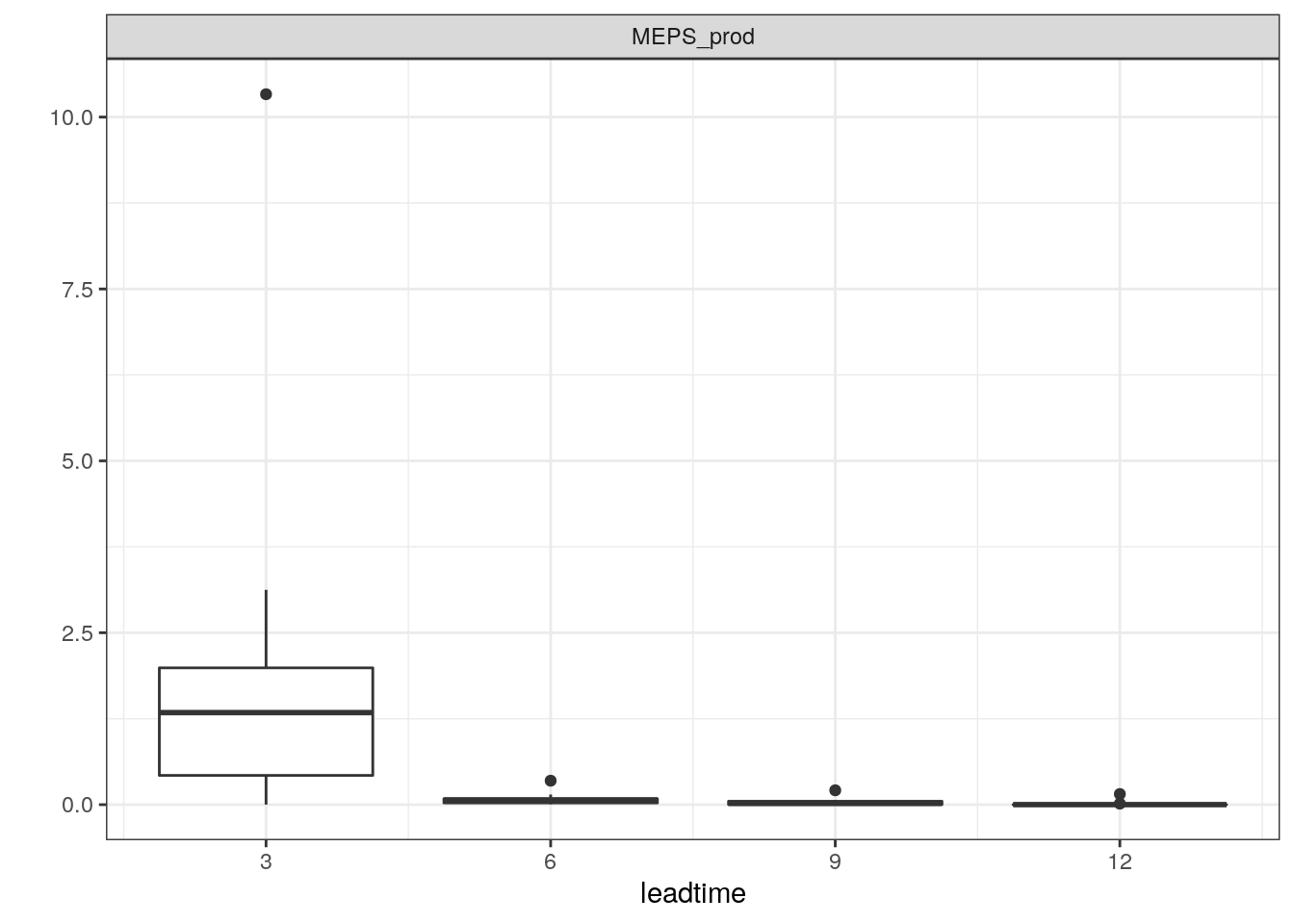
plot_station_eps(precip_3h, 1106, 2019021706, type = "stacked_prob") + scale_x_continuous(breaks = seq(0, 12, 3))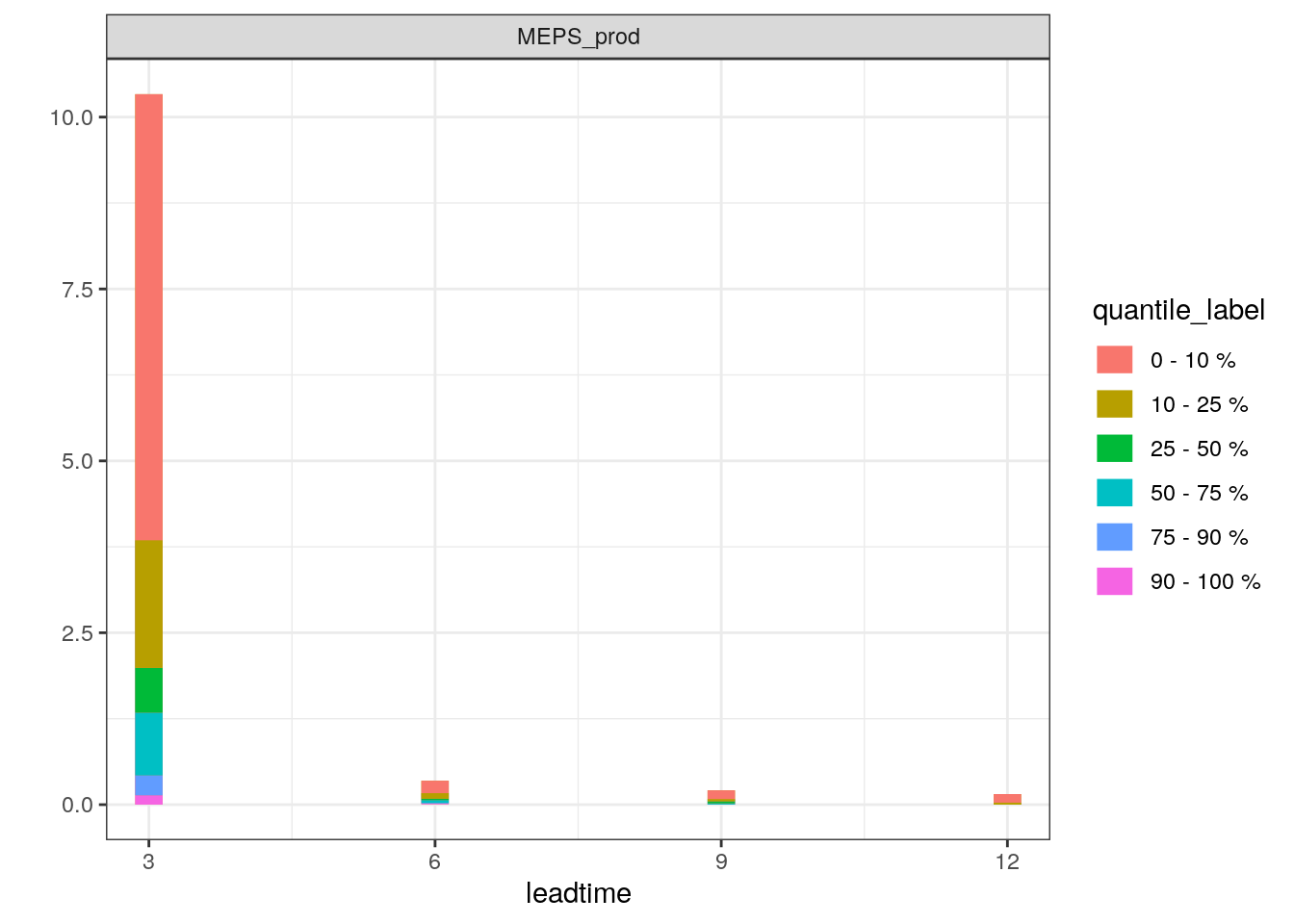
Your turn:
- Observations are read in the same way as we did for deterministic forecasts. Read in the observations for 2m temperature and 3h accumulated precipitation and join to the forecasts.
(t2m <- join_to_fcst(
t2m,
read_point_obs(
first_validdate(t2m),
last_validdate(t2m),
parameter = "T2m",
obs_path = here("data/OBSTABLE")
)
))## ● MEPS_prod
## # A tibble: 15,963 x 22
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1035 T2m
## # … with 15,953 more rows, and 17 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, T2m <dbl>(precip_3h <- join_to_fcst(
precip_3h,
read_point_obs(
first_validdate(precip_3h),
last_validdate(precip_3h),
parameter = "AccPcp3h",
obs_path = here("data/OBSTABLE")
)
))## ● MEPS_prod
## # A tibble: 6,369 x 22
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1117 Pcp
## 2 2019-02-17 00:00:00 2019-02-17 03:00:00 3 1098 Pcp
## 3 2019-02-17 00:00:00 2019-02-17 03:00:00 3 6249 Pcp
## 4 2019-02-17 00:00:00 2019-02-17 03:00:00 3 6286 Pcp
## 5 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2976 Pcp
## 6 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2382 Pcp
## 7 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2575 Pcp
## 8 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2667 Pcp
## 9 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2964 Pcp
## 10 2019-02-17 00:00:00 2019-02-17 03:00:00 3 2498 Pcp
## # … with 6,359 more rows, and 17 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, AccPcp3h <dbl>We can now add the observations to our plots
Note this function still needs more work, and doesn’t work well in all cases!
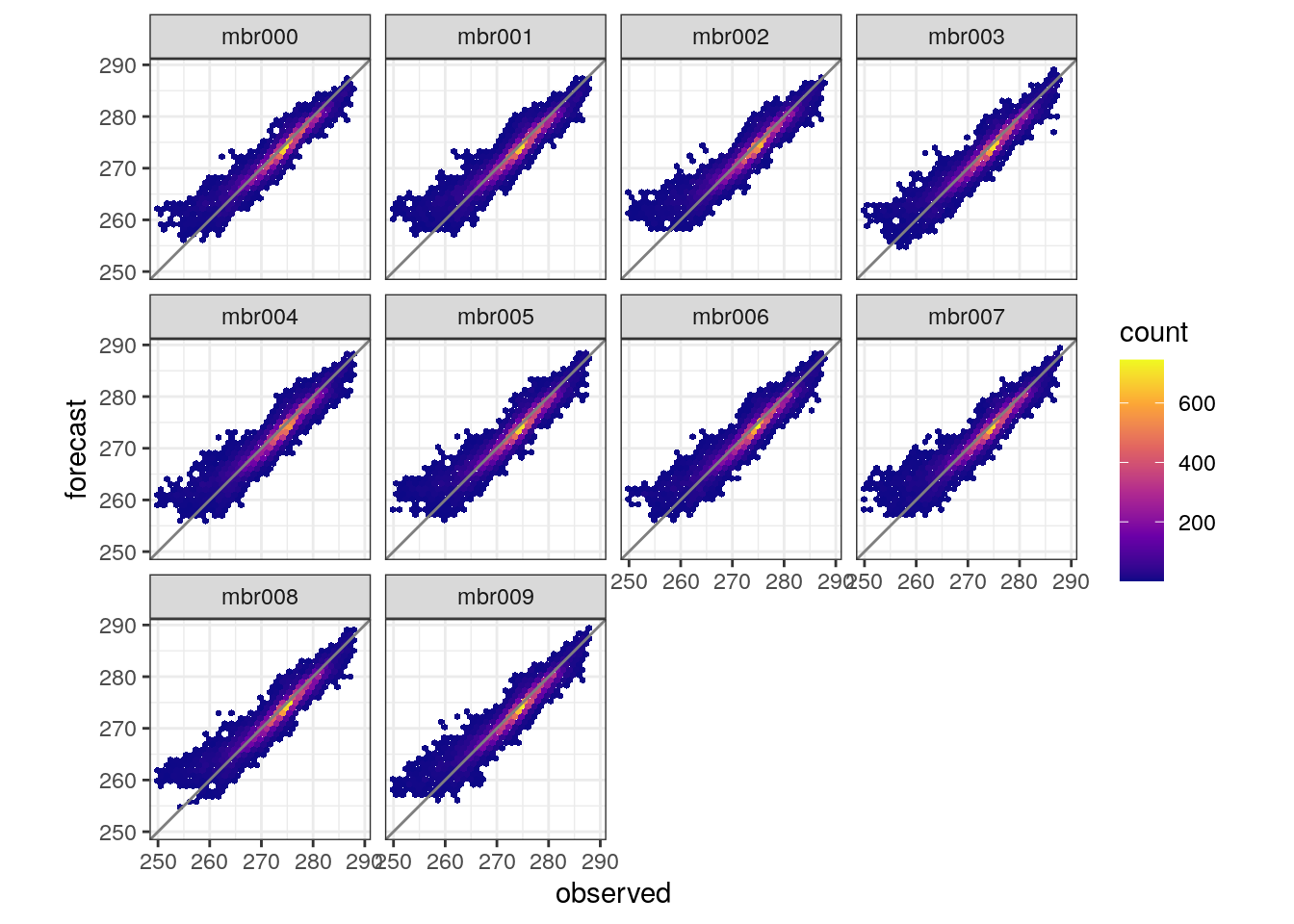
We can also make scatter plots of how forecasts compare with observations. They are made with hexbin plots and it is posisible to compare the whole ensemble with the observations or each ensemble member. The function is plot_scatter .
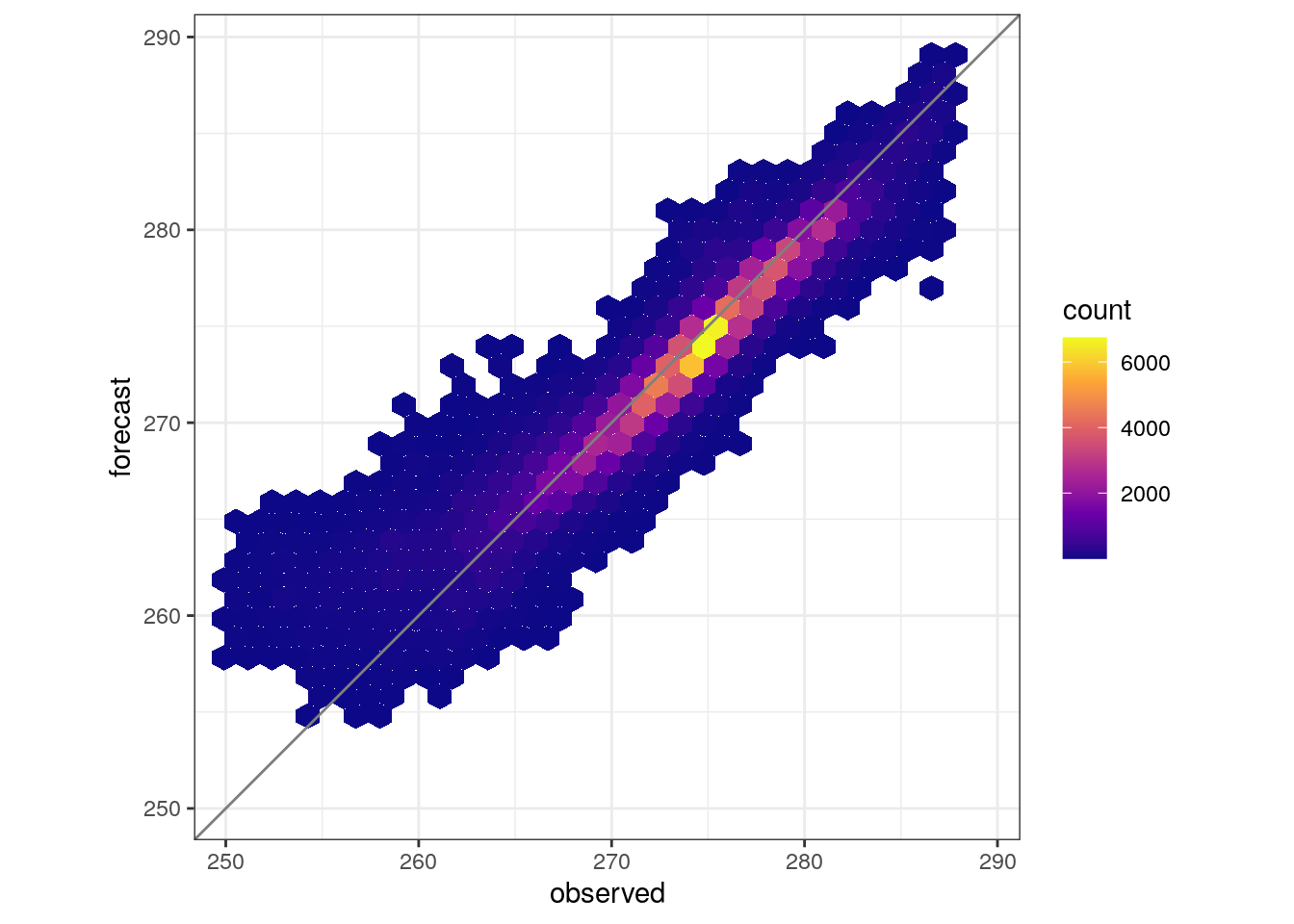
Your turn:
- Can you work out how to combine all members inta a single scatter plot. Check the help and note that the explanations are not complete!
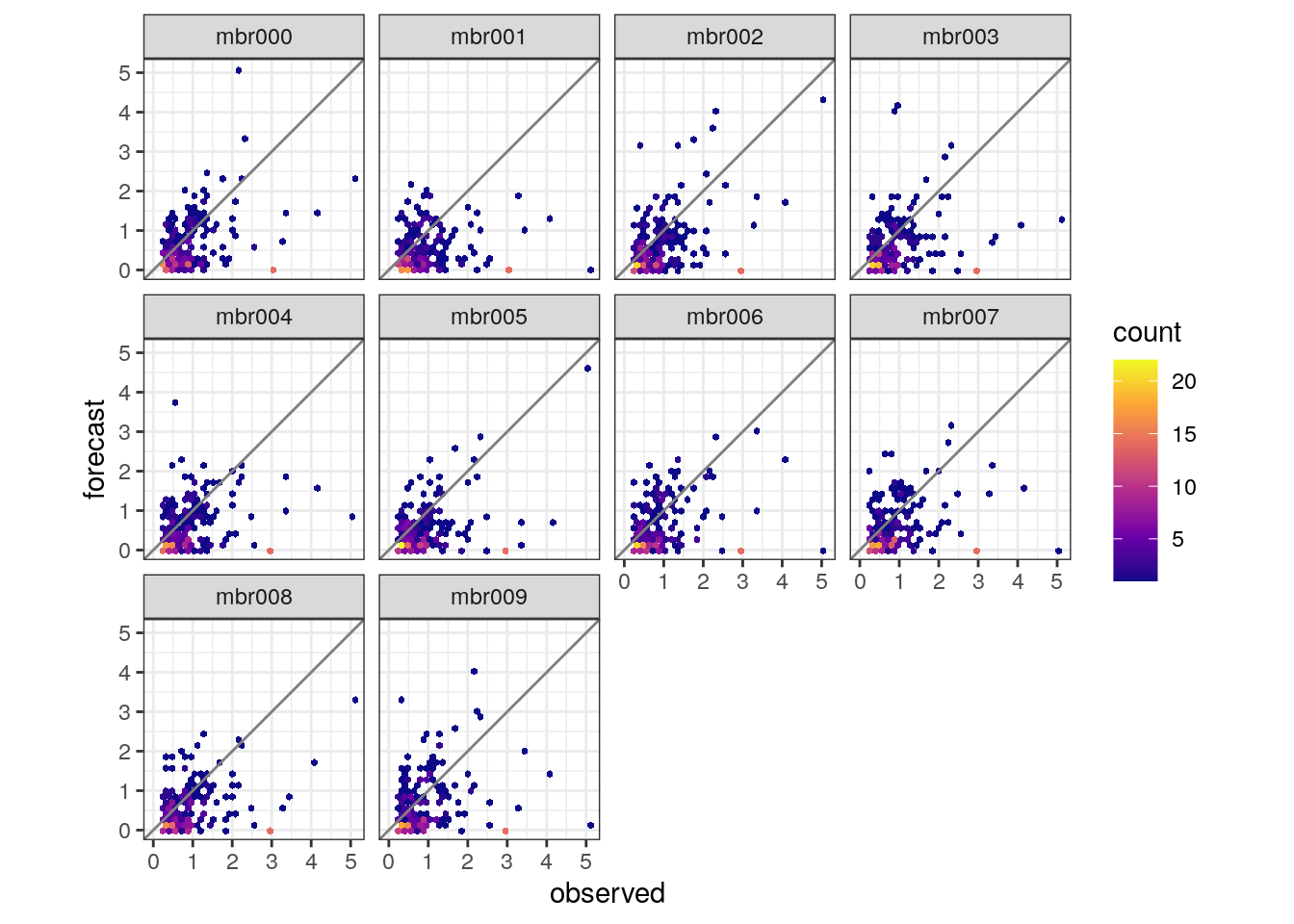
- Make a scatter plots for each member for observed 3h precipitation > 0.25 mm.
Solutions:
- Can you work out how to combine all members inta a single scatter plot. Check the help and note that the explanations are not complete!
- Make a scatter plots for each member for observed 3h precipitation > 0.25 mm.
4.3.1 Multi model ensembles
When we generated SQLite FCTABLE files for a fake multimodel ensemble we needed to specify a lot of details about the ensemble, such as the names and member numbers for each sub model. When we read those data in from the FCTABLE files, that information is already there. So, let’s read in our multi model ensemble and see what we get.
read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = "awesome_multimodel_eps",
fcst_type = "EPS",
parameter = "T2m",
lead_time = seq(0, 12, 3),
by = "6h",
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads"
)## ● awesome_multimodel_eps
## ● AROME_Arctic_prod
## # A tibble: 4,580 x 6
## fcdate validdate leadtime SID AROME_Arctic_pr…
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 270.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 274.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 273.
## # … with 4,570 more rows, and 1 more variable: fcst_cycle <chr>
##
## ● MEPS_prod
## # A tibble: 4,580 x 8
## fcdate validdate leadtime SID MEPS_prod_mbr000
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 268.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 275.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 274.
## # … with 4,570 more rows, and 3 more variables: MEPS_prod_mbr001 <dbl>,
## # MEPS_prod_mbr002 <dbl>, fcst_cycle <chr>As you can see we get the two sub models - AROME_Arctic_prod with one member, and MEPS_prod with 3 members - but not the full ensemble. However, we can create the full ensemble with the function merge_multimodel.
(t2m_mm <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = "awesome_multimodel_eps",
fcst_type = "EPS",
parameter = "T2m",
lead_time = seq(0, 12, 3),
by = "6h",
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads"
) %>%
merge_multimodel())## ● awesome_multimodel_eps
## # A tibble: 4,580 x 9
## fcdate validdate leadtime SID AROME_Arctic_pr…
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 270.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 274.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 273.
## # … with 4,570 more rows, and 4 more variables: fcst_cycle <chr>,
## # MEPS_prod_mbr000 <dbl>, MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>
##
## ● AROME_Arctic_prod(awesome_multimodel_eps)
## # A tibble: 4,580 x 6
## fcdate validdate leadtime SID AROME_Arctic_pr…
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 270.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 274.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 273.
## # … with 4,570 more rows, and 1 more variable: fcst_cycle <chr>
##
## ● MEPS_prod(awesome_multimodel_eps)
## # A tibble: 4,580 x 8
## fcdate validdate leadtime SID MEPS_prod_mbr000
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 268.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 275.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 274.
## # … with 4,570 more rows, and 3 more variables: MEPS_prod_mbr001 <dbl>,
## # MEPS_prod_mbr002 <dbl>, fcst_cycle <chr>Now we have the full multimodel ensemble and the two sub models, all as separate models in the harp_fcst object. You can, if you prefer, discard the sub models by setting keep_sub_models = FALSE in merge_multimodel.
Now we have two harp_fcst objects for 2m temperature, t2m and t2m_mm. We can easily combine them into a single harp_fcst using the standard concatenate function, c
## ● MEPS_prod
## # A tibble: 15,963 x 22
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1035 T2m
## # … with 15,953 more rows, and 17 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, T2m <dbl>
##
## ● awesome_multimodel_eps
## # A tibble: 4,580 x 9
## fcdate validdate leadtime SID AROME_Arctic_pr…
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 270.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 274.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 273.
## # … with 4,570 more rows, and 4 more variables: fcst_cycle <chr>,
## # MEPS_prod_mbr000 <dbl>, MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>
##
## ● AROME_Arctic_prod(awesome_multimodel_eps)
## # A tibble: 4,580 x 6
## fcdate validdate leadtime SID AROME_Arctic_pr…
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 270.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 274.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 273.
## # … with 4,570 more rows, and 1 more variable: fcst_cycle <chr>
##
## ● MEPS_prod(awesome_multimodel_eps)
## # A tibble: 4,580 x 8
## fcdate validdate leadtime SID MEPS_prod_mbr000
## <dttm> <dttm> <int> <int> <dbl>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 268.
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 275.
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 273.
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 275.
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 271.
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 272.
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 272.
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 272.
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 273.
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 274.
## # … with 4,570 more rows, and 3 more variables: MEPS_prod_mbr001 <dbl>,
## # MEPS_prod_mbr002 <dbl>, fcst_cycle <chr>4.3.2 Lagged ensembles
Reading lagged ensembles from FCTABLE files is also easier than in the conversion to SQLite step. Since FCTABLE files were saved for each forecast cycle, and the members for that cycle in the file, all we need to do is tell read_point_forecast the appropriate lags. Here we need to be a bit careful about what we’re doing, especially if we are reading in data from other models at the same. In the case of CMEPS there is a new set of ensemble members every three hours, but if we want to compare it with MEPS, which has a full set of members every six hours, which should set the by = "6h" and use our lags specification to ensure we read in the correct amount of data for CMEPS, by ensuring there are lags from zero to five hours. This probably becomes clearer with an example…
(t2m <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = c("CMEPS_prod", "MEPS_prod"),
fcst_type = "EPS",
parameter = "T2m",
lead_time = seq(0, 12, 3),
by = "6h",
lags = list(
CMEPS_prod = paste0(seq(0, 5), "h"),
MEPS_prod = "0h"
),
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads",
merge_lags = FALSE
))## ● CMEPS_prod
## # A tibble: 110,304 x 14
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 110,294 more rows, and 9 more variables: CMEPS_prod_mbr000 <dbl>,
## # CMEPS_prod_mbr001 <dbl>, CMEPS_prod_mbr003 <dbl>, CMEPS_prod_mbr004 <dbl>,
## # CMEPS_prod_mbr005 <dbl>, CMEPS_prod_mbr006 <dbl>, fcst_cycle <chr>,
## # model_elevation <dbl>, units <chr>
##
## ● MEPS_prod
## # A tibble: 22,980 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 22,970 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>There was a warning about missing files. This is because we didn’t generate any FCTABLE files for the 21 cycle on the 16 Feb 2019 and they were also not uploaded to this project! However, this illustrates that when lagging is used, you have to be very clear in your mind exactly what you need to get the lagged ensemble you want.
You will also see that there a are lot of missing data - this is immediately apparent for members 5 and 6. This is becasuse, since we set merge_lags = FALSE, we have only read in lagged data, but haven’t created the lagged ensemble yet. We create the lagged ensemble with the function lag_forecast. We tell the function which cycles you want to be the “parent” cycles and the function will shift all of the members between the parent cycles to the parent cycle. By default, children are found by looking backwards in time, as would happen in an operational setting - for example, if the parent cycles are 0, 6, 12 and 18, the child cycles for the parent at 6 are at 5, 4, 3, 2, and 1, and so on for the other parents. You can look for children in the other direction by setting direction = -1. Note that when merge_lags = TRUE, the ensemble is created with the parent cycles set to be those generated from the start_date, end_date and by arguments.
## ● CMEPS_prod
## # A tibble: 36,768 x 14
## fcst_cycle fcdate validdate leadtime SID parameter
## <chr> <dttm> <dttm> <dbl> <int> <chr>
## 1 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 00 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 36,758 more rows, and 8 more variables: CMEPS_prod_mbr000 <dbl>,
## # CMEPS_prod_mbr001 <dbl>, model_elevation <dbl>, units <chr>,
## # CMEPS_prod_mbr003 <dbl>, CMEPS_prod_mbr004 <dbl>, CMEPS_prod_mbr005 <dbl>,
## # CMEPS_prod_mbr006 <dbl>
##
## ● MEPS_prod
## # A tibble: 22,980 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 T2m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 T2m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 T2m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 T2m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 T2m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 T2m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 T2m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 T2m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1027 T2m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1033 T2m
## # … with 22,970 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>Your turn:
- Use
pull(.fcst, fcst_cycle) %>% map(unique) %>% map(sort)to see which cycles you are left with when you try differentparent_cyclesanddirection = 1ordirection = -1. Try to remember what we actually did when we ranread_eps_interpolatefor CMEPS - Combine 2m temperature forecasts for the multimodel ensemble (including sub models), MEPS_prod and CMEPS(with parent_cycles of 6, 12 and 18) and select the common cases and join the observations (note you will have to run
set_units(t2m_mm, "K")due to a bug inread_point_forecastthat drops that units column for multi model ensembles)
Solutions
- Use
pull(.fcst, fcst_cycle) %>% map(unique) %>% map(sort)to see which cycles you are left with when you try differentparent_cyclesanddirection = 1ordirection = -1.
## $CMEPS_prod
## [1] "00" "01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12" "13" "14"
## [16] "15" "16" "17" "18" "22" "23"
##
## $MEPS_prod
## [1] "00" "06" "12" "18"## $CMEPS_prod
## [1] "06" "12" "18"
##
## $MEPS_prod
## [1] "00" "06" "12" "18"## $CMEPS_prod
## [1] "00" "03" "06" "09" "12" "15" "18"
##
## $MEPS_prod
## [1] "00" "06" "12" "18"pull(lag_forecast(t2m, "CMEPS_prod", seq(0, 18, 6), direction = -1), fcst_cycle) %>% map(unique) %>% map(sort)## $CMEPS_prod
## [1] "00" "06" "12"
##
## $MEPS_prod
## [1] "00" "06" "12" "18"pull(lag_forecast(t2m, "CMEPS_prod", seq(0, 18, 3), direction = -1), fcst_cycle) %>% map(unique) %>% map(sort)## $CMEPS_prod
## [1] "00" "03" "06" "09" "12" "15"
##
## $MEPS_prod
## [1] "00" "06" "12" "18"- Combine 2m temperature forecasts for the multimodel ensemble (including sub models), MEPS_prod and CMEPS(with parent_cycles of 0, 6, 12 and 18) and select the common cases
(t2m <- c(set_units(t2m_mm, "K"), lag_forecast(t2m, "CMEPS_prod", seq(0, 18, 6))) %>%
common_cases() %>%
join_to_fcst(
read_point_obs(
first_validdate(.),
last_validdate(.),
parameter = "T2m",
obs_path = here("data/OBSTABLE")
)
)
)## ● awesome_multimodel_eps
## # A tibble: 1,955 x 14
## fcdate validdate leadtime SID fcst_cycle units
## <dttm> <dttm> <dbl> <int> <chr> <chr>
## 1 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 06 K
## 2 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 06 K
## 3 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 06 K
## 4 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 06 K
## 5 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 06 K
## 6 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 06 K
## 7 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 06 K
## 8 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1027 06 K
## 9 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1033 06 K
## 10 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1035 06 K
## # … with 1,945 more rows, and 8 more variables: AROME_Arctic_prod_mbr000 <dbl>,
## # MEPS_prod_mbr000 <dbl>, MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>,
## # lon <dbl>, lat <dbl>, elev <dbl>, T2m <dbl>
##
## ● AROME_Arctic_prod(awesome_multimodel_eps)
## # A tibble: 1,955 x 11
## fcdate validdate leadtime SID fcst_cycle units
## <dttm> <dttm> <dbl> <int> <chr> <chr>
## 1 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 06 K
## 2 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 06 K
## 3 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 06 K
## 4 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 06 K
## 5 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 06 K
## 6 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 06 K
## 7 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 06 K
## 8 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1027 06 K
## 9 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1033 06 K
## 10 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1035 06 K
## # … with 1,945 more rows, and 5 more variables: AROME_Arctic_prod_mbr000 <dbl>,
## # lon <dbl>, lat <dbl>, elev <dbl>, T2m <dbl>
##
## ● MEPS_prod(awesome_multimodel_eps)
## # A tibble: 1,955 x 13
## fcdate validdate leadtime SID fcst_cycle units
## <dttm> <dttm> <dbl> <int> <chr> <chr>
## 1 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 06 K
## 2 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 06 K
## 3 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 06 K
## 4 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 06 K
## 5 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 06 K
## 6 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 06 K
## 7 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 06 K
## 8 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1027 06 K
## 9 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1033 06 K
## 10 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1035 06 K
## # … with 1,945 more rows, and 7 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, lon <dbl>, lat <dbl>,
## # elev <dbl>, T2m <dbl>
##
## ● CMEPS_prod
## # A tibble: 1,955 x 24
## fcst_cycle fcdate validdate leadtime SID parameter
## <chr> <dttm> <dttm> <dbl> <int> <chr>
## 1 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 T2m
## 2 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 T2m
## 3 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 T2m
## 4 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 T2m
## 5 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 T2m
## 6 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 T2m
## 7 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 T2m
## 8 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1027 T2m
## 9 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1033 T2m
## 10 06 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1035 T2m
## # … with 1,945 more rows, and 18 more variables: CMEPS_prod_mbr000 <dbl>,
## # CMEPS_prod_mbr001 <dbl>, model_elevation <dbl>, units <chr>,
## # CMEPS_prod_mbr003 <dbl>, CMEPS_prod_mbr004 <dbl>, CMEPS_prod_mbr005 <dbl>,
## # CMEPS_prod_mbr006 <dbl>, CMEPS_prod_mbr000_lag <dbl>,
## # CMEPS_prod_mbr001_lag <dbl>, CMEPS_prod_mbr003_lag <dbl>,
## # CMEPS_prod_mbr004_lag <dbl>, CMEPS_prod_mbr005_lag <dbl>,
## # CMEPS_prod_mbr006_lag <dbl>, lon <dbl>, lat <dbl>, elev <dbl>, T2m <dbl>
##
## ● MEPS_prod
## # A tibble: 1,955 x 22
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <dbl> <int> <chr>
## 1 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 T2m
## 2 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 T2m
## 3 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 T2m
## 4 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 T2m
## 5 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 T2m
## 6 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 T2m
## 7 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 T2m
## 8 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1027 T2m
## 9 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1033 T2m
## 10 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1035 T2m
## # … with 1,945 more rows, and 17 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>, lon <dbl>, lat <dbl>,
## # elev <dbl>, T2m <dbl>Now we can try plotting the ensmeble temperature evolution for REIPA again
plot_station_eps(
t2m,
1114,
2019021706,
obs_column = T2m,
colour = "red",
shape = 21
) +
scale_x_continuous(breaks = seq(0, 9, 3))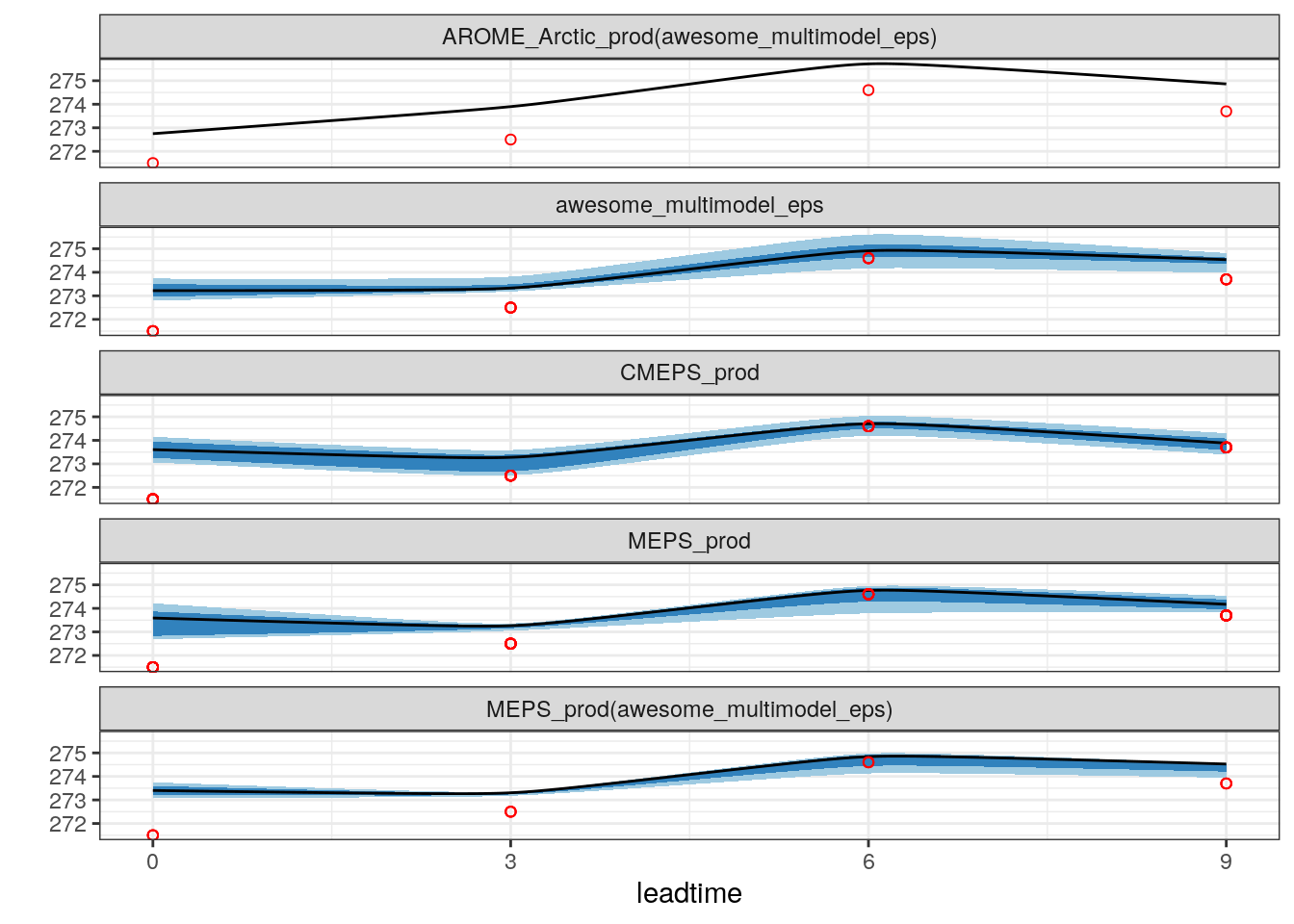
There are still a few problems with plot_station_eps so tread carefully!
4.3.3 Shifted forecasts
Let’s say you want to compare an ensmeble with another but with the time shifted. i.e. how does a forecast that is 6 hours old compare with the current forecast. We can do that by shifting the forecast - that means adjusting the forecast start time and the forecast lead time by 6 hours so the forecast appears to have been run at a different time. We can do this with shift_forecast.
To illustrate, we read in the MEPS_prod data, for 10m wind speed, just to be different!
s10m <- read_point_forecast(
start_date = 2019021700,
end_date = 2019021718,
fcst_model = "MEPS_prod",
fcst_type = "EPS",
parameter = "S10m",
lead_time = seq(0, 12, 3),
file_path = here("data/FCTABLE/ensemble"),
file_template = "fctable_eps_all_leads"
)And then we are going to create a new ensemble with MEPS_prod shifted by 6 hours, so the forecast that started at 00 UTC now appears to have started at 06 UTC etc. This means that the forecast with a lead time of 6 hours, that used to start at 00 UTC now appears to have started at 06 UTC and has a lead time of 0 hours.
## ● MEPS_prod
## # A tibble: 24,060 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <int> <int> <chr>
## 1 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1001 S10m
## 2 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1010 S10m
## 3 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1014 S10m
## 4 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1015 S10m
## 5 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1018 S10m
## 6 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1021 S10m
## 7 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1022 S10m
## 8 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1023 S10m
## 9 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1025 S10m
## 10 2019-02-17 00:00:00 2019-02-17 00:00:00 0 1026 S10m
## # … with 24,050 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>
##
## ● MEPS_prod_shifted_6h
## # A tibble: 14,436 x 18
## fcdate validdate leadtime SID parameter
## <dttm> <dttm> <dbl> <int> <chr>
## 1 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1001 S10m
## 2 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1010 S10m
## 3 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1014 S10m
## 4 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1015 S10m
## 5 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1018 S10m
## 6 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1021 S10m
## 7 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1022 S10m
## 8 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1023 S10m
## 9 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1025 S10m
## 10 2019-02-17 06:00:00 2019-02-17 06:00:00 0 1026 S10m
## # … with 14,426 more rows, and 13 more variables: MEPS_prod_mbr000 <dbl>,
## # MEPS_prod_mbr001 <dbl>, MEPS_prod_mbr002 <dbl>, MEPS_prod_mbr003 <dbl>,
## # MEPS_prod_mbr004 <dbl>, MEPS_prod_mbr005 <dbl>, MEPS_prod_mbr006 <dbl>,
## # MEPS_prod_mbr007 <dbl>, MEPS_prod_mbr008 <dbl>, MEPS_prod_mbr009 <dbl>,
## # fcst_cycle <chr>, model_elevation <dbl>, units <chr>So now we have two ensembles in our data: MEPS_prod and MEPS_prod_shifted_6h. We can see that they are different by getting the start times (fcdate) and lead times from each of the forecasts.
## $MEPS_prod
## # A tibble: 20 x 2
## fcdate leadtime
## <dttm> <int>
## 1 2019-02-17 00:00:00 0
## 2 2019-02-17 00:00:00 3
## 3 2019-02-17 00:00:00 6
## 4 2019-02-17 00:00:00 9
## 5 2019-02-17 00:00:00 12
## 6 2019-02-17 06:00:00 0
## 7 2019-02-17 06:00:00 3
## 8 2019-02-17 06:00:00 6
## 9 2019-02-17 06:00:00 9
## 10 2019-02-17 06:00:00 12
## 11 2019-02-17 12:00:00 0
## 12 2019-02-17 12:00:00 3
## 13 2019-02-17 12:00:00 6
## 14 2019-02-17 12:00:00 9
## 15 2019-02-17 12:00:00 12
## 16 2019-02-17 18:00:00 0
## 17 2019-02-17 18:00:00 3
## 18 2019-02-17 18:00:00 6
## 19 2019-02-17 18:00:00 9
## 20 2019-02-17 18:00:00 12
##
## $MEPS_prod_shifted_6h
## # A tibble: 12 x 2
## fcdate leadtime
## <dttm> <dbl>
## 1 2019-02-17 06:00:00 0
## 2 2019-02-17 06:00:00 3
## 3 2019-02-17 06:00:00 6
## 4 2019-02-17 12:00:00 0
## 5 2019-02-17 12:00:00 3
## 6 2019-02-17 12:00:00 6
## 7 2019-02-17 18:00:00 0
## 8 2019-02-17 18:00:00 3
## 9 2019-02-17 18:00:00 6
## 10 2019-02-18 00:00:00 0
## 11 2019-02-18 00:00:00 3
## 12 2019-02-18 00:00:00 6We’re going to want to verify s10m later, so let’s make sure we have the common cases and get the observations
4.3.4 Verification
For ensemble verification, the main verification function is ens_verify. Similar to det_verify, you give it the data and the column name of the observations.
## $ens_summary_scores
## # A tibble: 16 x 12
## mname leadtime num_cases mean_bias stde rmse spread spread_skill_ra…
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 awes… 0 467 0.177 1.40 1.41 0.744 0.526
## 2 awes… 3 509 0.552 2.09 2.16 0.713 0.330
## 3 awes… 6 472 0.596 2.34 2.42 0.710 0.294
## 4 awes… 9 507 0.782 2.33 2.46 0.798 0.325
## 5 MEPS… 0 467 0.187 1.55 1.56 0.756 0.486
## 6 MEPS… 3 509 0.572 2.09 2.16 0.754 0.348
## 7 MEPS… 6 472 0.612 2.35 2.42 0.734 0.303
## 8 MEPS… 9 507 0.798 2.32 2.45 0.811 0.330
## 9 CMEP… 0 467 0.0678 1.67 1.67 0.686 0.410
## 10 CMEP… 3 509 0.344 2.11 2.14 0.729 0.341
## 11 CMEP… 6 472 0.470 2.33 2.37 0.766 0.323
## 12 CMEP… 9 507 0.673 2.34 2.44 0.806 0.331
## 13 MEPS… 0 467 0.139 1.55 1.56 0.618 0.397
## 14 MEPS… 3 509 0.457 2.06 2.11 0.722 0.342
## 15 MEPS… 6 472 0.498 2.30 2.35 0.770 0.327
## 16 MEPS… 9 507 0.670 2.30 2.39 0.882 0.368
## # … with 4 more variables: rank_histogram <list>, crps <dbl>,
## # crps_potential <dbl>, crps_reliability <dbl>
##
## $ens_threshold_scores
## # A tibble: 0 x 0
##
## $det_summary_scores
## # A tibble: 120 x 9
## mname member leadtime sub_model num_cases bias rmse mae stde
## <chr> <chr> <dbl> <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 awesome_mul… mbr000 0 AROME_Arcti… 467 0.145 1.12 0.738 1.11
## 2 awesome_mul… mbr000 3 AROME_Arcti… 509 0.493 2.24 1.48 2.19
## 3 awesome_mul… mbr000 6 AROME_Arcti… 472 0.550 2.49 1.65 2.43
## 4 awesome_mul… mbr000 9 AROME_Arcti… 507 0.733 2.58 1.72 2.47
## 5 awesome_mul… mbr000 0 MEPS_prod 467 0.155 1.55 1.09 1.55
## 6 awesome_mul… mbr000 3 MEPS_prod 509 0.479 2.11 1.42 2.05
## 7 awesome_mul… mbr000 6 MEPS_prod 472 0.525 2.32 1.55 2.26
## 8 awesome_mul… mbr000 9 MEPS_prod 507 0.689 2.39 1.63 2.30
## 9 awesome_mul… mbr001 0 MEPS_prod 467 -0.0784 1.59 1.17 1.59
## 10 awesome_mul… mbr001 3 MEPS_prod 509 0.399 2.03 1.39 1.99
## # … with 110 more rows
##
## attr(,"parameter")
## [1] "T2m"
## attr(,"start_date")
## [1] "2019021706"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 180By default, summary deterministic verification scores will be computed for each member. We can also compute categorical ensemble scores based on thresholds (such as Brier Score, ROC, economic value etc.) if we pass some thresholds to the function
You can also compute “fair” scores for CRPS and Brier Score, which take account differences in the number of members between ensembles by scaling them to an equal number of members. We do this by passing num_ref_members.
So now we can have a quick look at some score plots using plot_point_verif - the default for the type of verification is verif_type = "ens" so we don’t need to specify it (for now)
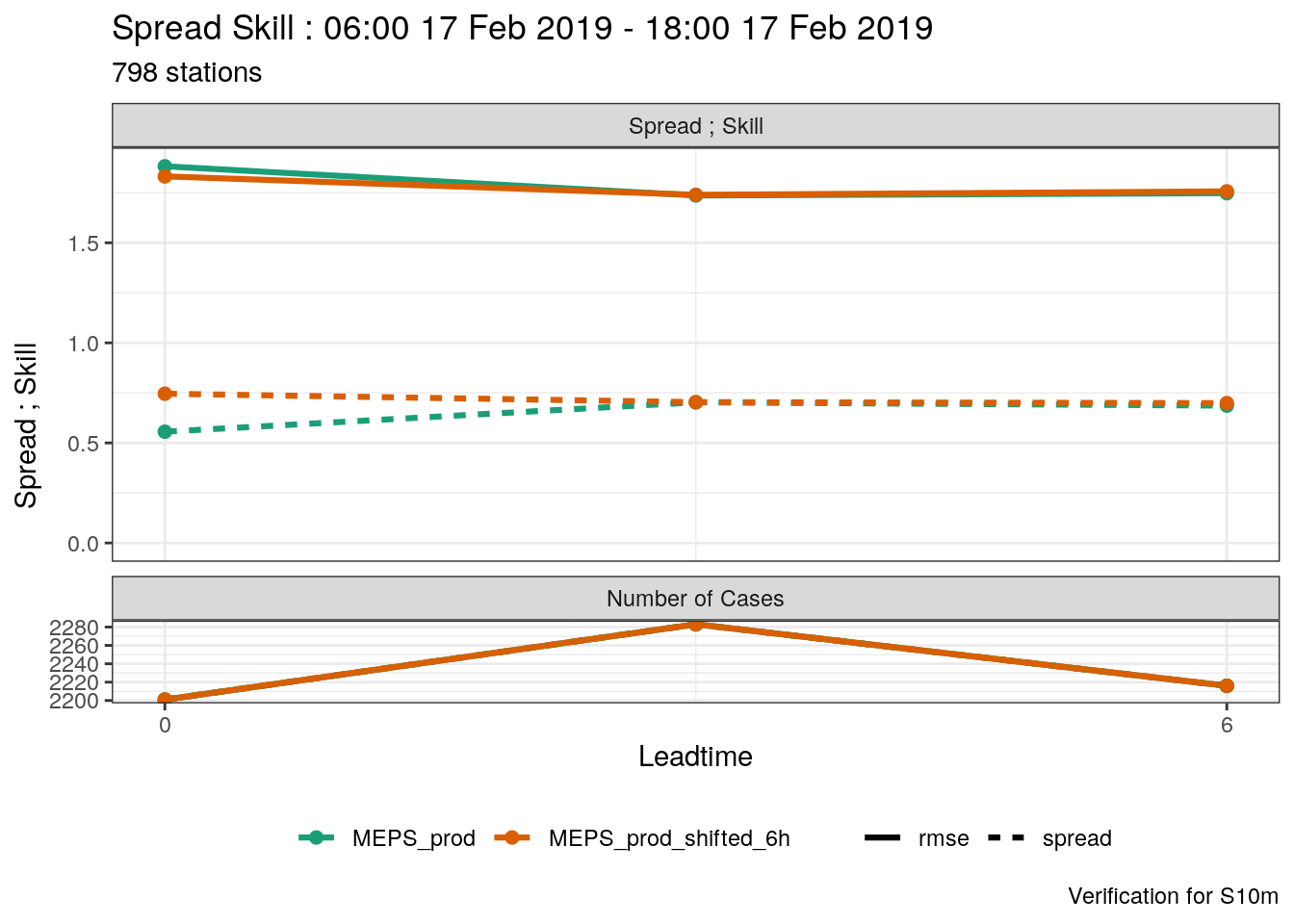
plot_point_verif(verif_s10m, rank_histogram)
plot_point_verif(verif_t2m, spread_skill_ratio)
plot_point_verif(verif_t2m, fair_crps)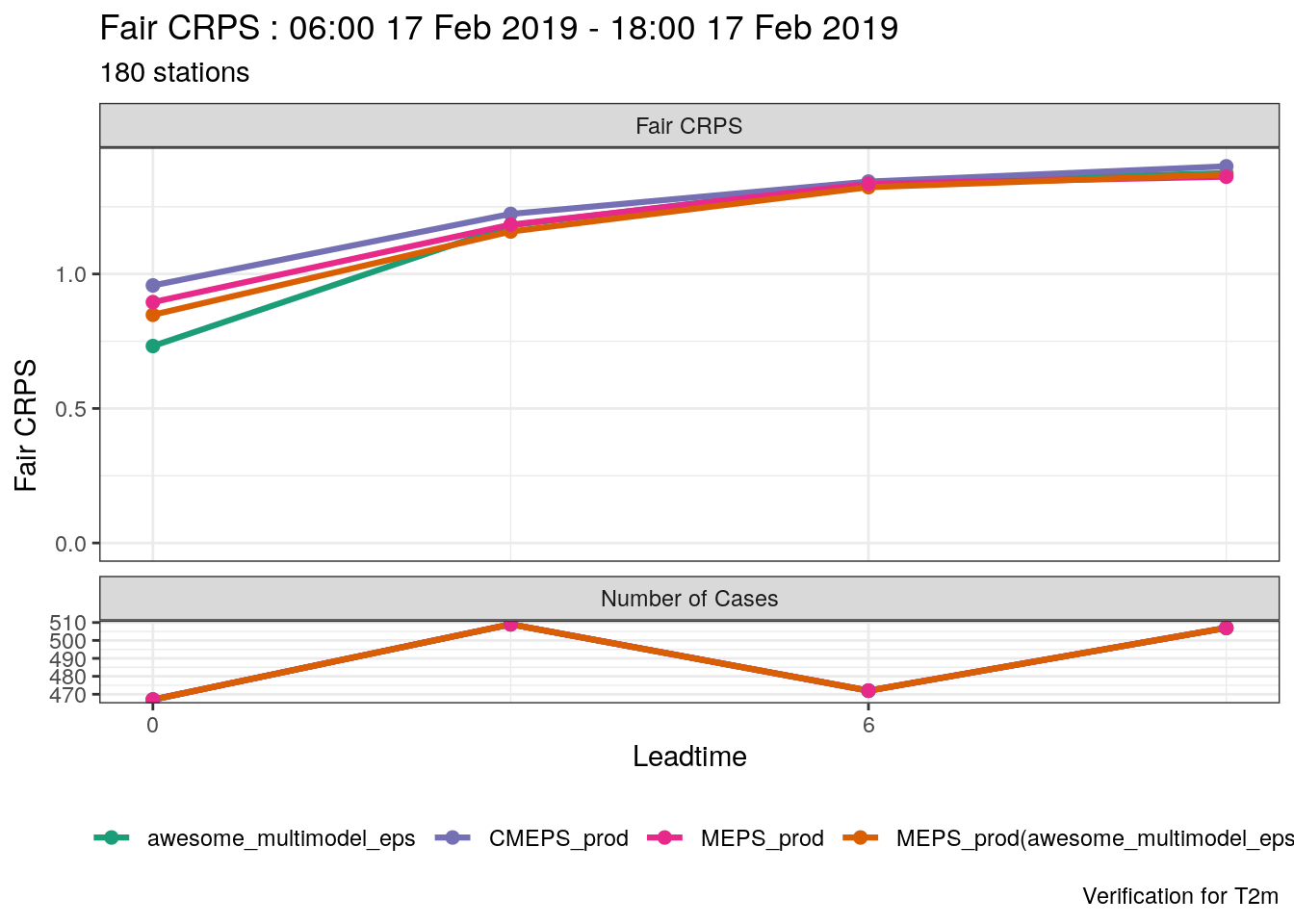
plot_point_verif(
verif_t2m,
rank_histogram,
facet_by = vars(leadtime),
num_facet_cols = 2,
num_legend_rows = 2
) +
theme(axis.text.x = element_text(angle = 90))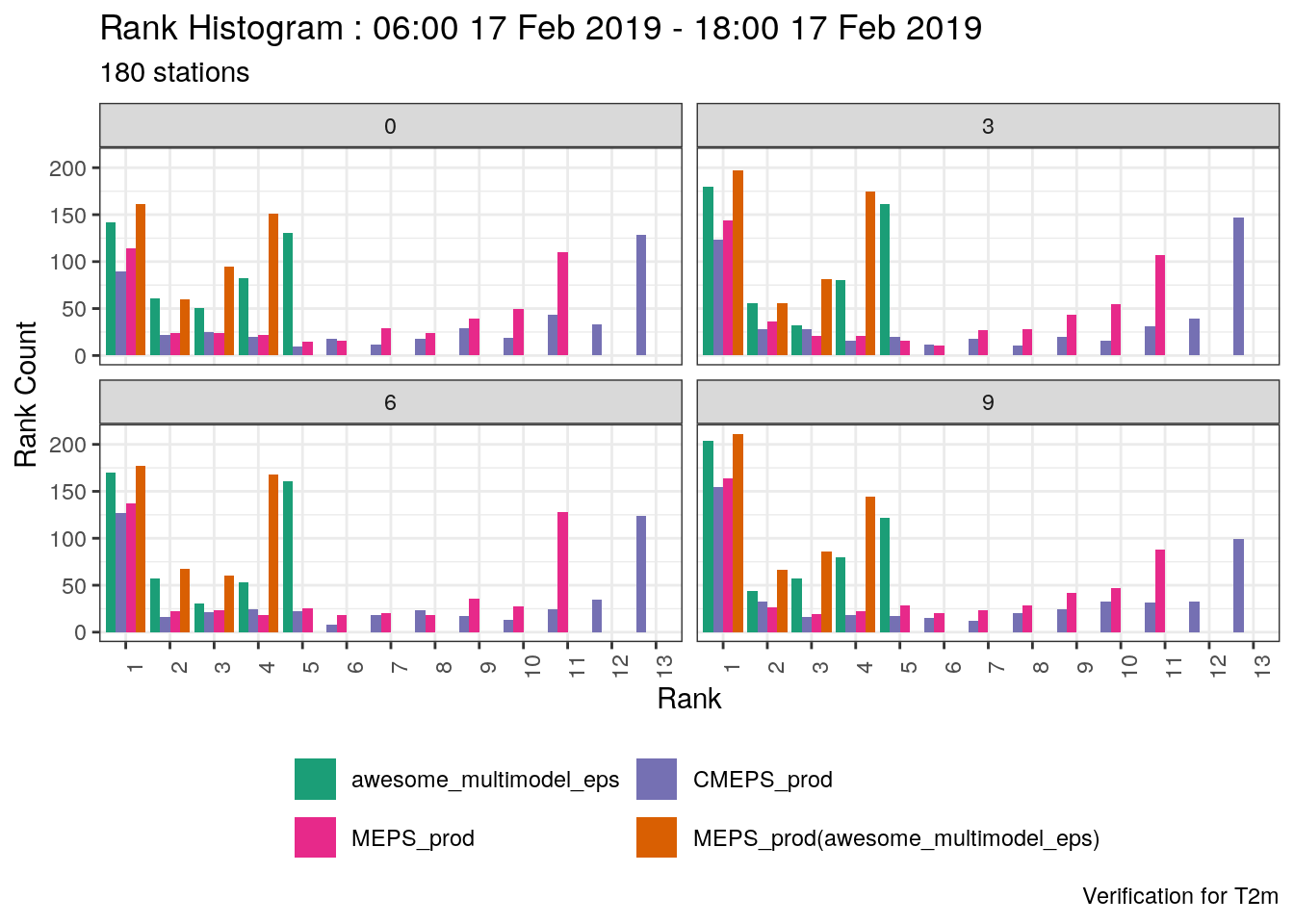
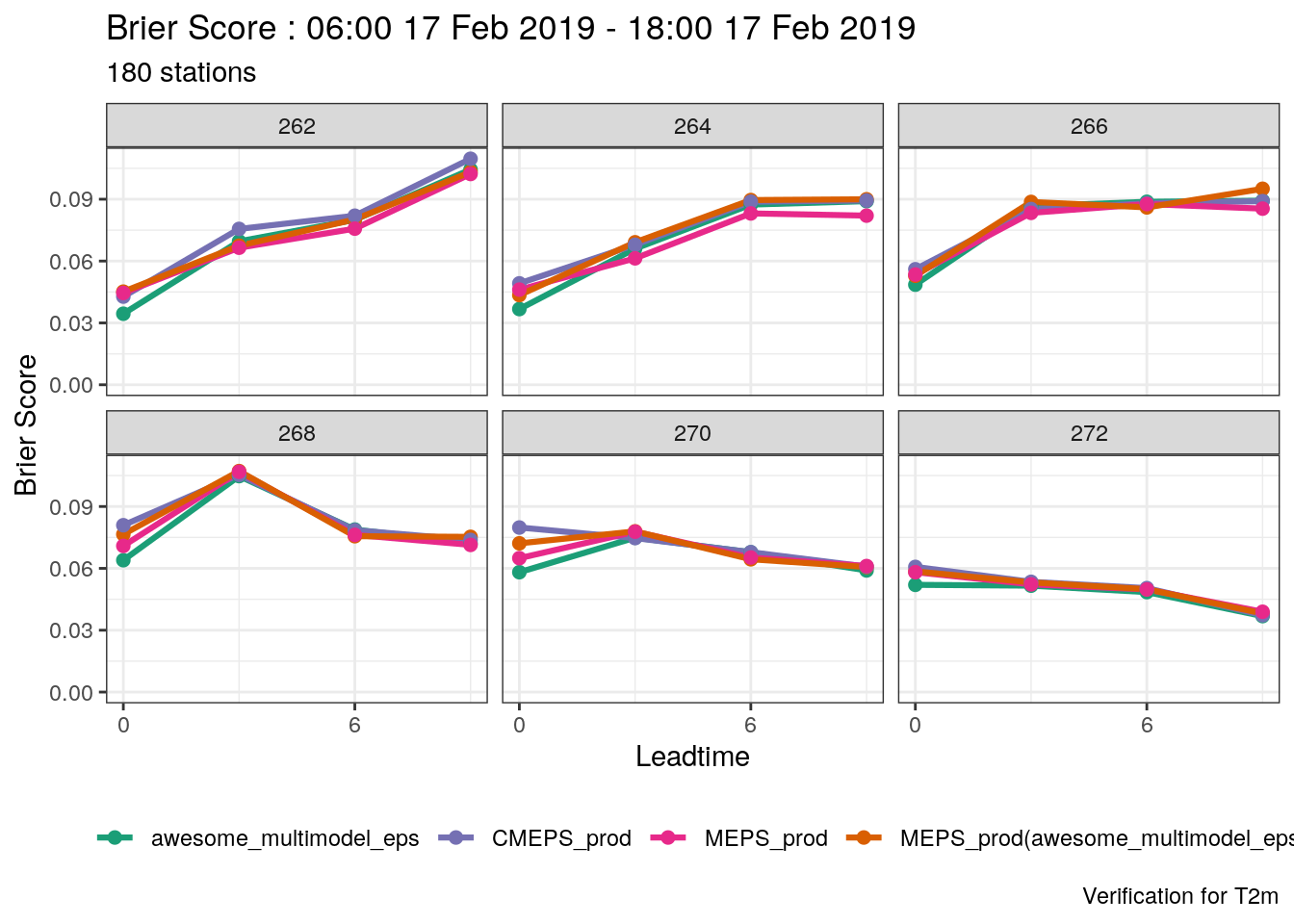
We can also set the colours / fill colours for our plots by passing a data frame with one column as mname and the other as colour. The easiest way to get the model names for the mname is either from the forecast object using names, or if that is not available at the time you can get if from the verification list.
## [1] "awesome_multimodel_eps"
## [2] "AROME_Arctic_prod(awesome_multimodel_eps)"
## [3] "MEPS_prod(awesome_multimodel_eps)"
## [4] "CMEPS_prod"
## [5] "MEPS_prod"## [1] "awesome_multimodel_eps"
## [2] "MEPS_prod(awesome_multimodel_eps)"
## [3] "CMEPS_prod"
## [4] "MEPS_prod"
## [5] "AROME_Arctic_prod(awesome_multimodel_eps)"my_colours <- tibble(
mname = names(t2m),
colour = c("darkblue", "blue", "skyblue", "red", "green")
)We can also plot the deterministic scores for each member. Here we need to tell plot_point_verif to do faceting by mname and to colour the lines according to the ensemble member.
plot_point_verif(
verif_t2m,
mae,
verif_type = "det",
facet_by = vars(mname),
colour_by = member,
legend_position = "right",
num_legend_rows = 20
)
We’ve got quite a lot going on there and it’s not a useful for plot, put we can clean it up by adding some more grouping variables. First let’s differentiate between the control members and the perturbed members.
verif_t2m$det_summary_scores <- mutate(
verif_t2m$det_summary_scores,
member_type = case_when(
grepl("000", member) ~ "control",
TRUE ~ "perturbed"
)
)
member_colours <- tribble(
~member_type, ~colour,
"control", "red",
"perturbed", "grey70"
)
plot_point_verif(
verif_t2m,
mae,
verif_type = "det",
facet_by = vars(mname),
colour_by = member_type,
colour_table = member_colours,
legend_position = "right",
num_legend_rows = 2,
group = member
)
And then we’re going to add an extra column to the data frame so that we can give lagged members a different line type
verif_t2m$det_summary_scores <- mutate(
verif_t2m$det_summary_scores,
lagging = case_when(
grepl("_lag$", member) ~ "lagged",
TRUE ~ "unlagged"
)
)
plot_point_verif(
verif_t2m ,
mae,
verif_type = "det",
facet_by = vars(mname),
colour_by = member_type,
colour_table = member_colours,
linetype_by = fct_rev(lagging),
legend_position = "right",
num_legend_rows = 2,
group = member
)
And finally, although our multi model ensemble plot looks strange, because it has 2 member 0s, that’s OK because we don’t need it as the data are in the plots for the sub models.
plot_point_verif(
verif_t2m ,
mae,
verif_type = "det",
facet_by = vars(mname),
colour_by = member_type,
colour_table = member_colours,
linetype_by = fct_rev(lagging),
legend_position = "right",
num_legend_rows = 2,
group = member,
filter_by = vars(mname != "awesome_multimodel_eps"),
num_facet_cols = 2
) +
scale_x_continuous(breaks = seq(0, 9, 3))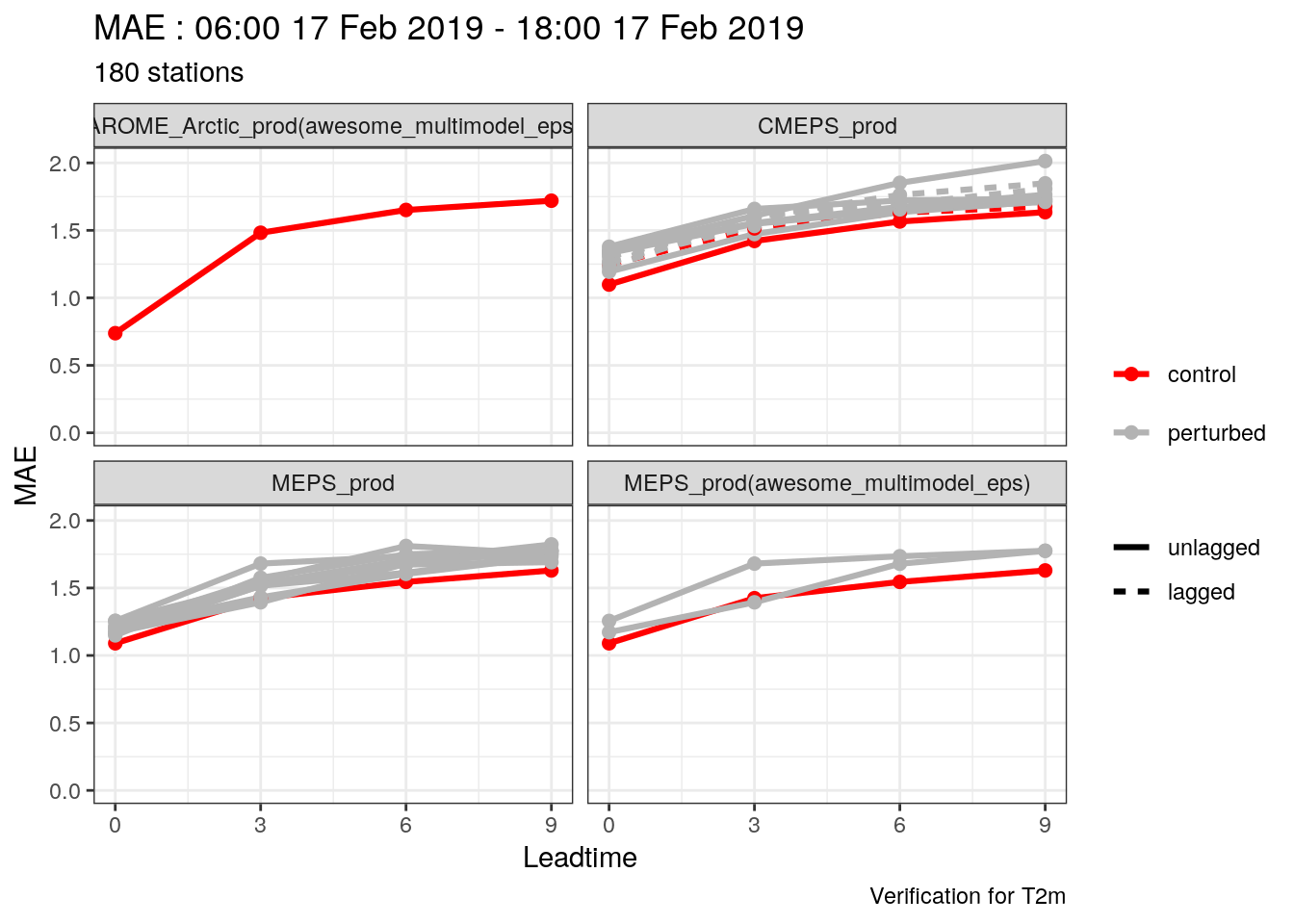
4.3.5 Verification by groups
As we mentioned in the deterministic section, we can compute verification scores for groups of data. So in our data we have forecasts from 3 different cycles: 06, 12, and 18 UTC. (Let’s forget for a moment that also means only 3 forecasts and assume that the data include forecasts from several days running with the same start times every day). We can use the groupings argument to say that we want to verify for each lead time for each forecast cycle.
## $ens_summary_scores
## # A tibble: 48 x 13
## mname leadtime fcst_cycle num_cases mean_bias stde rmse spread
## <chr> <dbl> <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 awes… 0 06 147 0.0532 1.02 1.01 0.525
## 2 awes… 0 12 166 -0.131 1.01 1.01 0.523
## 3 awes… 0 18 154 0.626 1.90 1.99 1.06
## 4 awes… 3 06 170 -0.0961 1.33 1.33 0.505
## 5 awes… 3 12 169 0.825 1.76 1.93 0.542
## 6 awes… 3 18 170 0.929 2.77 2.91 0.988
## 7 awes… 6 06 166 -0.337 1.22 1.26 0.499
## 8 awes… 6 12 154 1.23 2.48 2.76 0.627
## 9 awes… 6 18 152 0.970 2.79 2.95 0.946
## 10 awes… 9 06 169 0.708 1.81 1.94 0.624
## # … with 38 more rows, and 5 more variables: spread_skill_ratio <dbl>,
## # rank_histogram <list>, crps <dbl>, crps_potential <dbl>,
## # crps_reliability <dbl>
##
## $ens_threshold_scores
## # A tibble: 0 x 0
##
## $det_summary_scores
## # A tibble: 360 x 10
## mname member leadtime fcst_cycle sub_model num_cases bias rmse mae
## <chr> <chr> <dbl> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 awes… mbr000 0 06 AROME_Ar… 147 0.0882 0.836 0.526
## 2 awes… mbr000 3 06 AROME_Ar… 170 -0.139 1.36 1.03
## 3 awes… mbr000 6 06 AROME_Ar… 166 -0.307 1.30 0.981
## 4 awes… mbr000 9 06 AROME_Ar… 169 0.708 1.91 1.34
## 5 awes… mbr000 0 12 AROME_Ar… 166 0.0626 0.825 0.560
## 6 awes… mbr000 3 12 AROME_Ar… 169 0.788 1.97 1.37
## 7 awes… mbr000 6 12 AROME_Ar… 154 1.25 2.84 2.06
## 8 awes… mbr000 9 12 AROME_Ar… 170 0.907 3.26 2.25
## 9 awes… mbr000 0 18 AROME_Ar… 154 0.287 1.55 1.13
## 10 awes… mbr000 3 18 AROME_Ar… 170 0.830 3.05 2.05
## # … with 350 more rows, and 1 more variable: stde <dbl>
##
## attr(,"parameter")
## [1] "T2m"
## attr(,"start_date")
## [1] "2019021706"
## attr(,"end_date")
## [1] "2019021718"
## attr(,"num_stations")
## [1] 180But this only computes the scores for each forecast cycle and not for all of the cycles combined. We can rectify that by passing the groupings as a list with different grouping combinations
verif_t2m <- ens_verify(
t2m,
T2m,
groupings = list("leadtime", c("leadtime", "fcst_cycle")),
thresholds = seq(262, 272, 2)
)If we pull out the fcst_cycle column, we will see that we now have a new entry for all cycles.
## [1] " 06; 12; 18" "06" "12" "18"So we can plot for all forecast cycles
plot_point_verif(
verif_t2m,
brier_score_decomposition,
facet_by = vars(fcst_cycle, threshold),
num_facet_cols = 6
)
If we’ve computed some different verifications and we want to plot them together, we can join those score objects using bind_point_verif. We have done verification for 2m temperature and 10m wind speed, so we can bind those together.
verif_s10m <- ens_verify(
s10m,
S10m,
thresholds = c(1, 2, 5, 8),
groupings = list("leadtime", c("leadtime", "fcst_cycle"))
)
verif_all <- bind_point_verif(verif_t2m, verif_s10m)And then we can plot those together with the same function
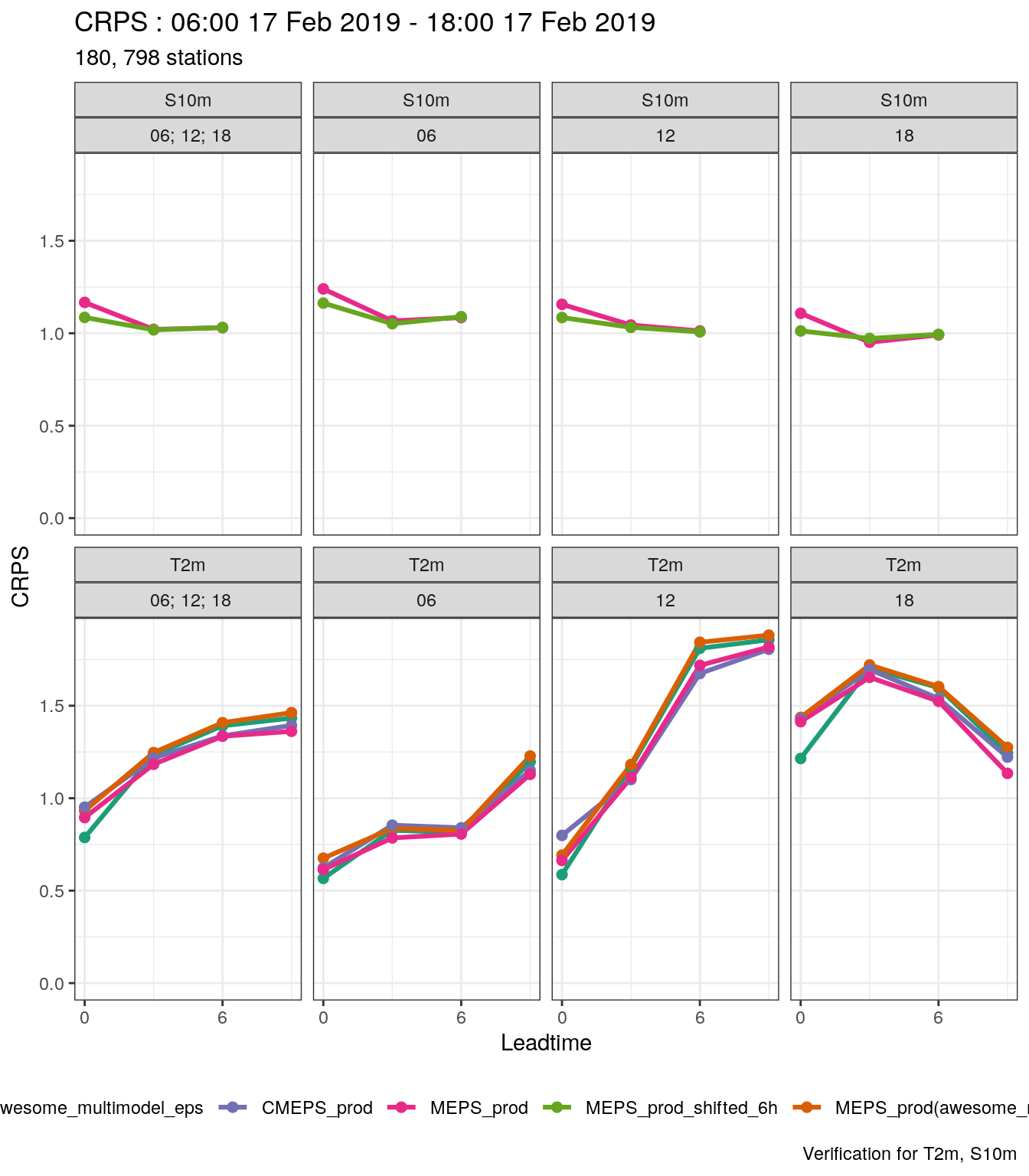
4.3.6 Saving the verification data
You can save your verification data with the function save_point_verif. You simply give it the data and the directory you want to save in. The filenames are generated from the data, so although you can provide a template, it is best not to.
save_point_verif(verif_t2m, verif_path = here("data/verification"))
save_point_verif(verif_s10m, verif_path = here("data/verification"))Once the data are saved you can use a browser based app to view and interact with the data. This app is created in the R package shiny, so to launch it you run the function shiny_plot_point_verif and give it the starting directory to look for data.